Sig工程 - 第7部分 - Solana 验证器 AccountsDB和Gossip内存优化
- syndica
- 发布于 2025-05-07 23:57
- 阅读 1533
本文介绍了Sig工程团队对Solana验证器进行的内存优化,包括为AccountsDB实现新的缓冲池,以及为Gossip Table提供新的后端,显著减少了Gossip的内存占用。通过自定义Buffer Pool替代mmap,减少了内存占用,并提升了I/O性能。同时,通过数据导向设计,使用SplitUnionList结构优化了Gossip Table的内存存储,减少了内存浪费。
本篇是我们将定期发布的 Sig 工程更新系列博客文章的第 7 部分。你可以在这里(https://blog.syndica.io/tag/engineering/)找到其它的 Sig 工程文章。
这篇博文详细介绍了最近对现有 Sig 组件所做的优化,包括为 AccountsDB 实现新的缓冲池,以及一种新的 Gossip Table 后端,它大大减少了 Gossip 的内存占用。
AccountsDB - 新的缓冲池
AccountsDB 是 Solana 的账户数据库,它将公钥地址映射到链上账户。我们最近通过从头开始实现一个新的缓冲池,重新设计了 AccountsDB 的内存管理。本节将解释我们为什么要进行这种改变,以及我们获得了哪些好处。
Solana 的账户总数正迅速接近 数十亿,需要数百 GB 的存储空间。这些大多数账户都存储在磁盘上的“账户文件”中,使得磁盘 I/O 成为优化的主要领域之一。
注意:有关 AccountsDB 的更多信息,请参阅我们的博文 AccountsDB 这里。
mmap 的工作原理
最初,Sig 使用 mmap 系统调用从这些文件中读取账户数据。mmap 告诉 Linux 的内存管理子系统创建一个新的虚拟内存区域 (VMA),这是一个连续的虚拟内存空间范围。虚拟内存和物理内存由称为“页”的块组成,通常为 4 KiB。一个 VMA 可以跨越许多虚拟内存页,并保存其内存区域的重要元数据,如页面保护。我们使用 mmap 为我们想要在 AccountsDB 中访问的每个磁盘上的账户文件创建一个只读 VMA。
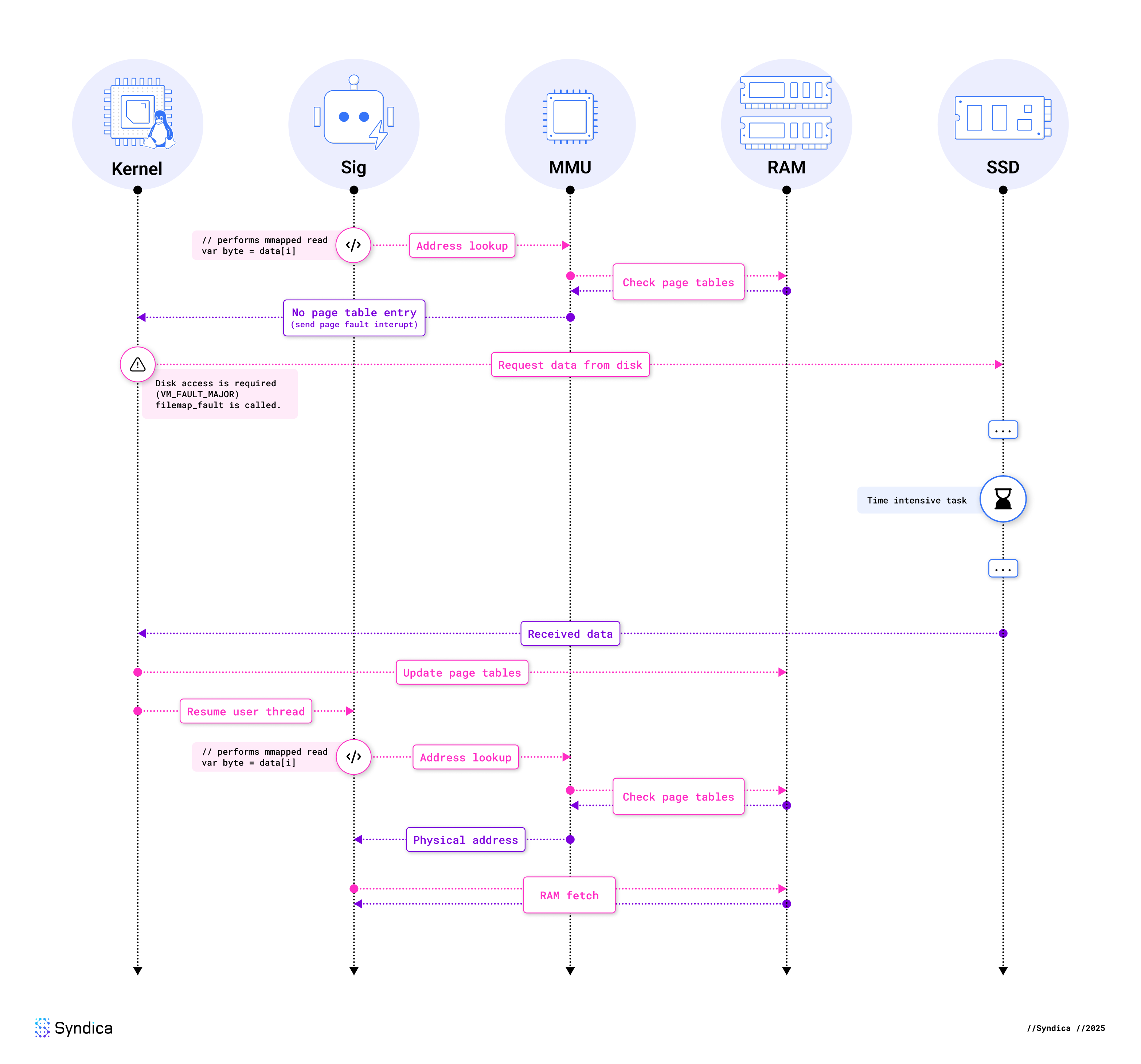
以这种方式使用 mmap 的一个好处是,它允许我们编写代码,就好像所有文件都完全在内存中一样。不幸的是,这比这更复杂。当我们从这些文件之一读取数据时,我们可能会得到一个“缺页故障”。缺页故障是内存管理单元 (MMU) 在访问的虚拟内存地址在物理内存中没有相应的页时引发的异常。下面是一个在这种情况下缺页故障如何发生的图:
 🔍 点击图片放大
🔍 点击图片放大
注意:为了简单起见,我们已经忽略了 CPU 的一些部分,如 TLB 和缓存。然而,在需要磁盘的缺页故障的上下文中,这些细节是不相关的,因为它们也高度依赖于架构。
正如你所看到的,内核的工作是解决缺页故障。为了从磁盘读取,内核分配一个新的物理内存页,并用来自磁盘的数据填充它。然后,内核将其页表中的虚拟内存页映射到这个新的物理页。
当然,实现比这复杂得多。以下是 Linux 内核在幕后所做事情的摘要:
- 调用了
handle_mm_fault,启动(非特定于架构的)缺页故障处理。 - 由于我们的映射是只读的,内核最终会调用
do_read_fault。 - 当我们调用
mmap时,我们使用了一个文件,这意味着 VMA 的元数据包括我们的文件系统提供的函数指针。现在我们出现了故障,vma→vm_ops→fault被调用,在我们的例子中,它是由ext4_file_mmap设置的。 - 对于典型的文件系统,这个函数将是
filemap_fault,内核在这里与其页面缓存子系统交互。如果页面不在页面缓存中,这被认为是主缺页故障。 - 然后它调用
page_cache_ra_unbounded(“ra” 代表预读),它急切地将文件读入页面缓存。在大多数情况下,内核将从磁盘读取比解决当前缺页故障所需的数据更多,假设应用程序很快会读取额外的数据。要提前读取,此函数分配页面,可能导致页面驱逐,并将它们添加到内核的文件映射中。 - 当数据不在文件映射中时,将调用
read_pages,它提交 IO 批处理并调用文件系统。 - 一旦所有数据都存在,
finish_fault将更新页表。 - 当上述步骤完成后,用户模式线程可以恢复。
总之,访问文件支持的内存映射区域会导致缺页故障,这可以通过页面缓存执行阻塞磁盘 IO。
mmap 用于 IO 的缺点
虽然 mmap 帮助我们快速开发 AccountsDB,但在用于 IO 的其他系统调用上,它的使用有很多不明显的缺陷。
高内存使用率和压力
在 Solana 验证器的上下文中,最重要的问题之一是与使用 mmap 相关的内存使用量增加。Linux 内核使用它的页面缓存来优化访问:当发生单个缺页故障时,内核会在页面缓存中读取它前后的一些页面。这有助于顺序读取的性能,因为较少的缺页故障会导致稍后在磁盘 IO 上阻塞。然而,这不仅对随机读取(我们的主要用例)没有帮助,而且还浪费了大量内存,并成倍增加了我们正在执行的磁盘 IO 量。这些页面在通常意义上没有被标记为“已使用”内存,因为它们随时可以被驱逐。容易回收的内存听起来并没有太大的危害,但它大大增加了系统范围内的内存压力,甚至可能导致具有大量可用内存的 Linux 系统开始使用交换。
无法控制驱逐
如前所述,内核几乎可以随时驱逐页面缓存拥有的页面——它们是可回收的。虽然可以自动处理这些很方便,但对于任何数据库来说,这都不是理想的选择;Linux 有一些关于页面访问的粗略数据,但在应用程序中控制页面驱逐允许我们做出更明智的决策。
没有非阻塞 API
在故障(和页面缓存未命中)时,内核以对故障进程完全不透明的方式执行阻塞磁盘 IO。这意味着阻塞 IO 牢固地阻塞了访问映射数据的线程;更好的方法是允许我们在等待磁盘时做一些有用的工作,但 mmap 没有异步 API。即使使用现代驱动器,等待磁盘读取也可能花费数百微秒;读取大量映射数据的线程可能会将大部分时间花在 IO 上。
隐藏的阻塞成本
由于我们对内核的缺页故障控制很少,因此昂贵的操作最终可能会出现在意想不到的地方。与显式文件读取调用相比,指向映射文件的指针可以很容易地散布在你的代码中,让你在不认为你有它们的地方进行阻塞操作。此外,这可能会使分析你的代码更加困难,因为不打算阻塞的代码(例如异步代码)可能会微妙地阻塞线程。
隐藏的竞争和 TLB 刷新
缺页故障还有另一种隐藏昂贵操作的方式,因为它们依赖于不断更改页表。修改页表需要锁定,这由内核处理。当然,这是一个竞争的来源:大量使用缺页故障会导致多线程应用程序中的竞争,从而阻碍读取带宽。一个相关的问题是遍历页表,这不是免费的,因此每个 CPU 核心都维护一个转换后备缓冲区 (TLB),这是最近的虚拟到物理内存转换的缓存。我们之前在图表中省略了这一点,但从概念上讲,它是 MMU 的一部分,这意味着 MMU 在需要转换地址时不需要检查 RAM 中的页表。当内核驱逐页面时,它会使它们从虚拟内存空间中失效,这意味着内核需要告诉每个 CPU 核心刷新其 TLB。这被称为 TLB shootdown,它擦除了每个核心 MMU 最近的转换。这些问题意味着,奇怪的是,在一个线程中大量使用 mmap 可能会偷偷地减慢进程中所有其他线程的速度。
无法跟上 NVMe
近年来,NVMe SSD 的读取带宽得到了显著提升,新的消费级 SSD 达到了 10GB/秒以上。由于使用 mmap 进行磁盘 IO 的性能问题,mmap 无法再跟上当今存储提供的带宽。利用 NVMe 的队列来达到其潜在带宽的必要性加剧了这种情况,而 mmap 不太可能有效地使用它。
结论
总之,依赖 mmap 进行磁盘 IO 有许多显著的性能缺陷:内存使用量增加、内存压力增加、页面驱逐不佳、没有非阻塞 API 以及几个意外的成本。在某种程度上,可以调整 mmap,但这些都是根本性问题。我们能做得更好吗?
Sig 的缓冲池
正如解释的那样,我们不想依赖内核的页面缓存或缺页故障;然而,完全进行无缓存读取也不是理想的选择。因此,我们需要一个进程内的页面缓存替代品,一个允许我们显式管理内存的缓冲池,这正是我们实现的。
缓冲池是由应用程序管理的内存帧缓存,它保存最近使用的数据以加速读取和写入。当程序请求数据时,缓冲池会检查它是否已加载到现有帧中。如果是,则立即处理该请求。如果不是,缓冲池会显式地从磁盘读取数据到空闲内存帧中,并在必要时驱逐旧帧。
我们的缓冲池实现 使用许多固定大小和对齐的帧,当前配置为每个 512 字节。这些帧在内存的大型区域中连续分配。请注意,选择的帧大小很重要——较大的帧大小允许更少的开销,但也会导致更高的内存使用率,并且读取的内容超过了我们的需要。我们选择此大小是因为超过 95% 的账户为 200 字节或更少,这意味着单个 512 字节的对齐读取足以读取大多数账户。
对于每个帧,我们存储两个原子元数据:引用计数和它是否包含有效数据。每个帧也由一个分层 FIFO跟踪,它指导驱逐。为了查找帧,我们使用标准的哈希图。
我们当前的实现在我们的大多数基准测试中都击败了 mmap,同时仍然有许多潜在的优化可用。更重要的是,我们已经显式控制了 AccountsDB 中的内存使用量,避免了 mmap 的高内存使用率和内存压力。由于现在预先分配了缓冲池的所有内存,我们的系统现在可以执行得更可预测。我们还从内核手中接管了驱逐控制权,并使我们的阻塞操作显式化。
基准
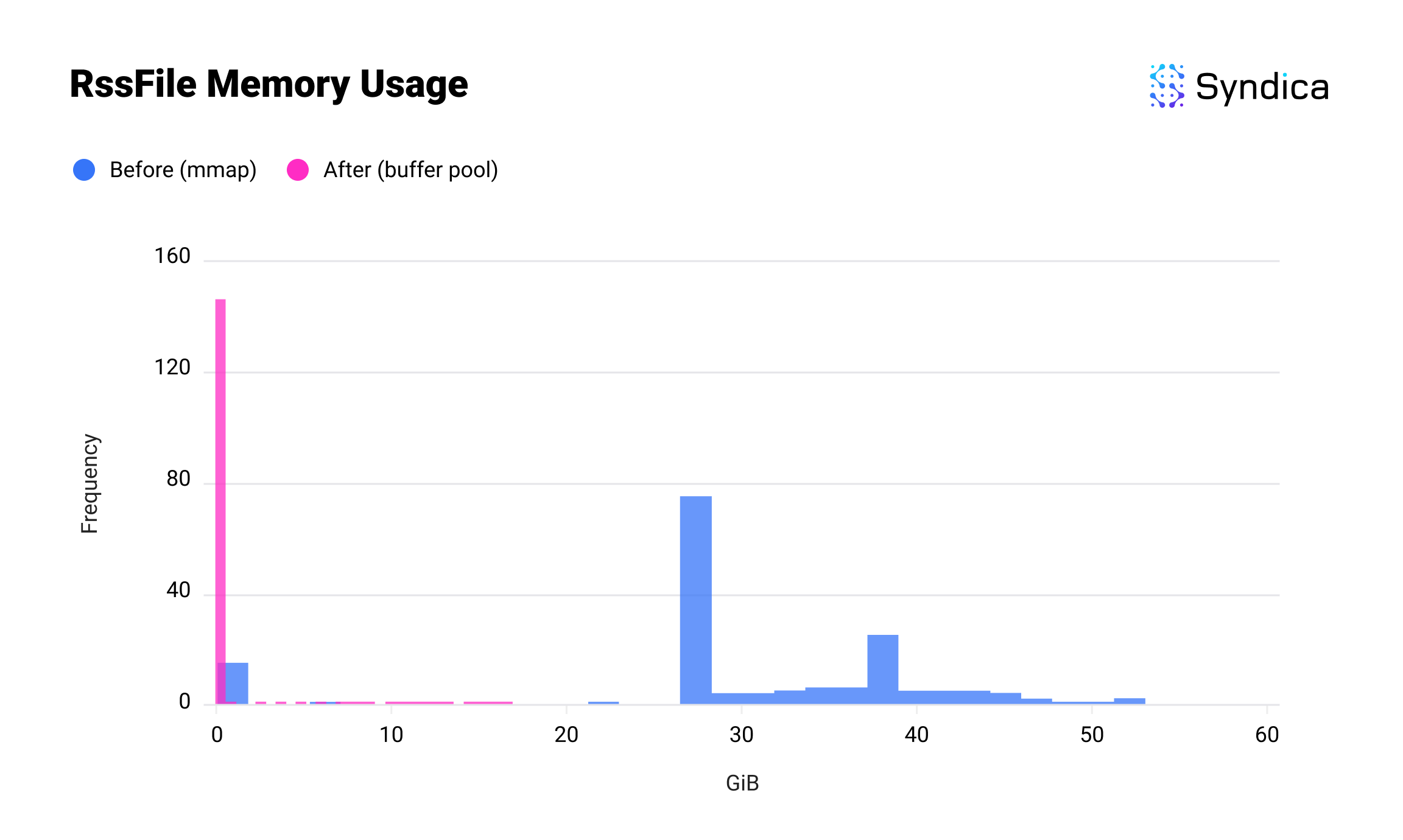
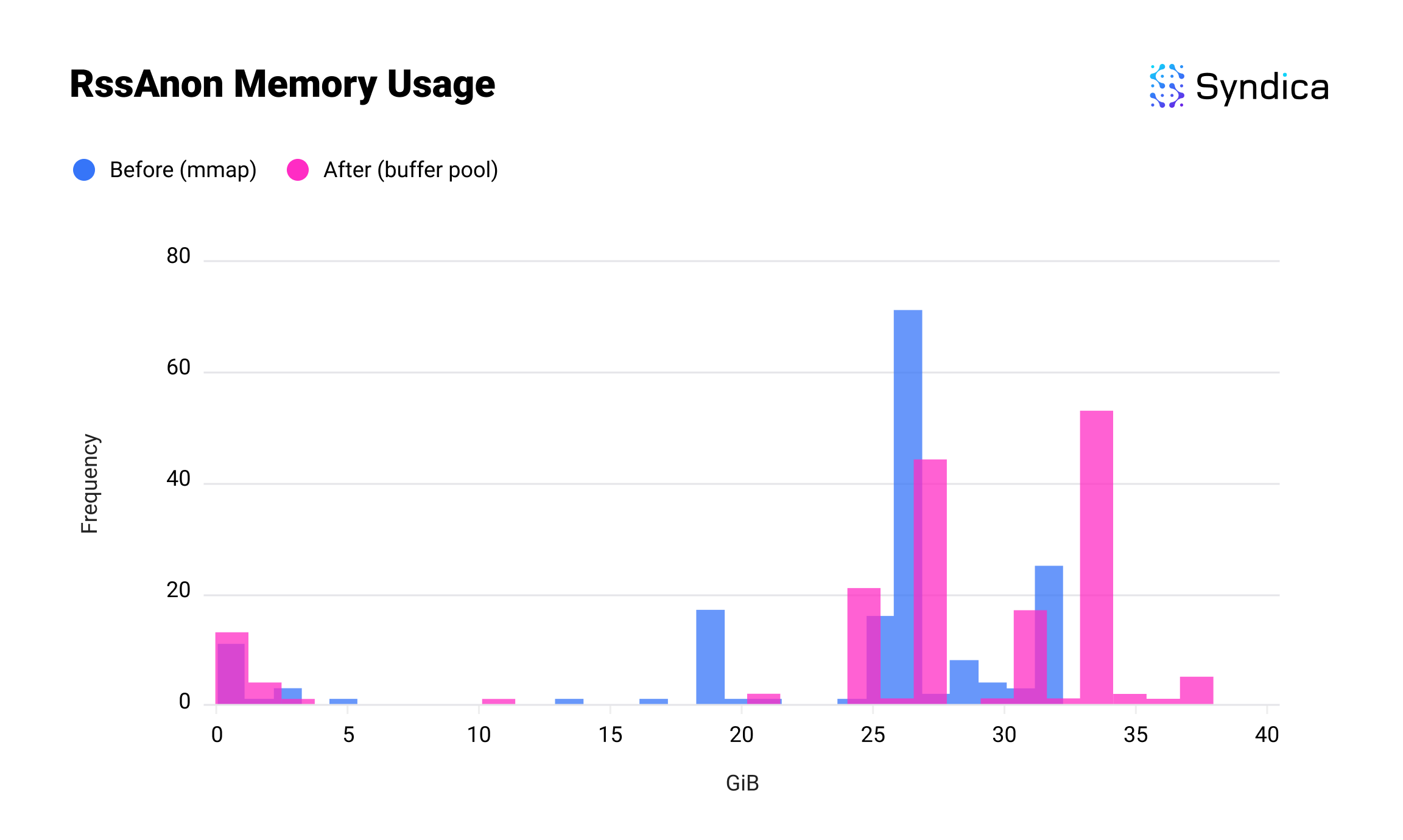
我们通过对每个实现执行 150 次基准测试来比较 mmap 和缓冲池的内存使用情况。由于内存使用率因运行而异,我们使用下面的直方图来可视化结果:x 轴显示使用了多少内存,y 轴显示有多少次运行使用了该数量。
第一个结果是 Sig 对 RssFile 内存的使用情况。RssFile 指的是驻留数据(即当前在 RAM 中的数据),用于文件映射。在引入缓冲池之后,此内存使用量从数十 GB 下降到大约为零;如果你能看到底部的一小段粉红色,这是因为账户索引,它与此更改分开。
 🔍 点击图片放大
🔍 点击图片放大
这是 RssAnon 的使用情况。RssAnon 或匿名内存占物理 RAM 中所有未由文件支持的普通内存分配。这个略高一些,因为我们将原本在 RssFile 中的内存引入到 RssAnon 中,但总和明显更低。
 🔍 点击图片放大
🔍 点击图片放大
虽然这通过将内存管理从内核移到 Sig 中引入了复杂性,但这是必要的,以将性能提高到内核的通用优化所能提供的程度。初步基准测试表明,我们的缓冲池在内存效率和吞吐量方面都优于 mmap。
我们在路线图上的未来改进包括:
- 创建一个专为并发访问设计的哈希图。
- 多个页面大小,类似于 Linux 的 HugePages,将减少读取较大账户的开销。
- 用于预取账户数据的非阻塞函数。
- 使用
O_DIRECT标志打开账户文件,该标志绕过内核的页面缓存。由于我们已经在用户空间中管理缓冲区,因此内核缓存是多余的,浪费内存并引入竞争。 - 默认情况下使用
io_uring,它已实现但目前已禁用,因为它需要一些更改才能提高性能。
有关完整的差异和一些基准测试,请查看拉取请求。
Gossip 内存优化
Gossip 是一种使节点能够相互连接并共享元数据的协议。它是我们在 Sig 中实现的第一个组件,因为它对于验证器中的所有其他组件都至关重要。它也是我们的第一篇博文的主题,你可以在这里阅读。至少,任何 Solana 验证器(无论是完整节点还是轻客户端)都需要运行 Gossip,因此我们希望它尽可能高效地运行。
在本节中,我们将探讨我们为 Gossip 实现的内存优化,该优化应用面向数据的设计来有效地存储相关数据的组。
内存使用率
Gossip Table 是用于 Gossip 的基本数据结构。它是一个内存数据库,用于存储通过 Gossip 接收的所有数据。在 mainnet 上,我们发现 Gossip Table 的内存使用率通常达到 GB 级别,其中大多数内存都浪费为空白空间。当作为简单的 Gossip 客户端运行时,这占了 Sig 大多数的内存使用率。
问题:低效的标签联合
效率低下源于 Gossip Table 存储许多不同类型的数据,每种类型都有不同的大小,但每种类型都存储在足够大的槽中,以容纳 任何 允许的数据类型。在 Gossip Table 中,这个“槽”是一个称为 GossipData 的标签联合。
💡
_什么是标签联合?_ 标签联合是一种分配内存区域以保存几种不同类型中的任何一种的方法。它包含两个部分:标签(标识它包含的数据类型的数字)和有效负载(指定类型的实际数据,例如 ContactInfo)。
为了适应 任何 允许的数据类型,有效负载必须始终是 最大 数据类型的大小。这是因为联合的大小必须在编译代码时确定,但它包含的项目的类型直到稍后,在运行时才会知道。
这就是 GossipData 的定义方式:
pub const GossipData = union(GossipDataTag) {
LegacyContactInfo: LegacyContactInfo,
Vote: struct { u8, Vote },
LowestSlot: struct { u8, LowestSlot },
LegacySnapshotHashes: LegacySnapshotHashes,
AccountsHashes: AccountsHashes,
EpochSlots: struct { u8, EpochSlots },
LegacyVersion: LegacyVersion,
Version: Version,
NodeInstance: NodeInstance,
DuplicateShred: struct { u16, DuplicateShred },
SnapshotHashes: SnapshotHashes,
ContactInfo: ContactInfo,
RestartLastVotedForkSlots: RestartLastVotedForkSlots,
RestartHeaviestFork: RestartHeaviestFork,
RestartHeaviestFork: RestartHeaviestFork,
};
这些是 GossipData 支持的数据类型的大小:
| 数据类型 | 大小(字节) |
|---|---|
| ContactInfo | 608 |
| LegacyContactInfo | 368 |
| { u8, Vote } | 168 |
| RestartLastVotedForkSlots | 144 |
| SnapshotHashes | 128 |
| RestartHeaviestFork | 96 |
| { u8, LowestSlot } | 96 |
| { u16, DuplicateShred } | 80 |
| Version | 64 |
| { u8, EpochSlots } | 64 |
| LegacyVersion | 56 |
| LegacySnapshotHashes | 56 |
| NodeInstance | 56 |
| AccountsHashes | 56 |
ContactInfo 是允许的最大类型,为 608 字节,并且标签为 4 字节,这意味着 GossipData 的每个实例都需要 612 字节。然而,许多项比这小得多,例如 EpochSlots,它只需要 64 字节。将 EpochSlots 存储在足够大的标签联合中以容纳 ContactInfo 会在空白空间上浪费 544 字节。
在 mainnet 上,不到 1% 的 Gossip 项是 ContactInfo,而近 90% 是 EpochSlots,从而导致大量空间浪费。这种设计在 Sig 和 Agave 中都很常见,因此两个客户端都有类似的内存浪费。
解决方案:面向数据的存储
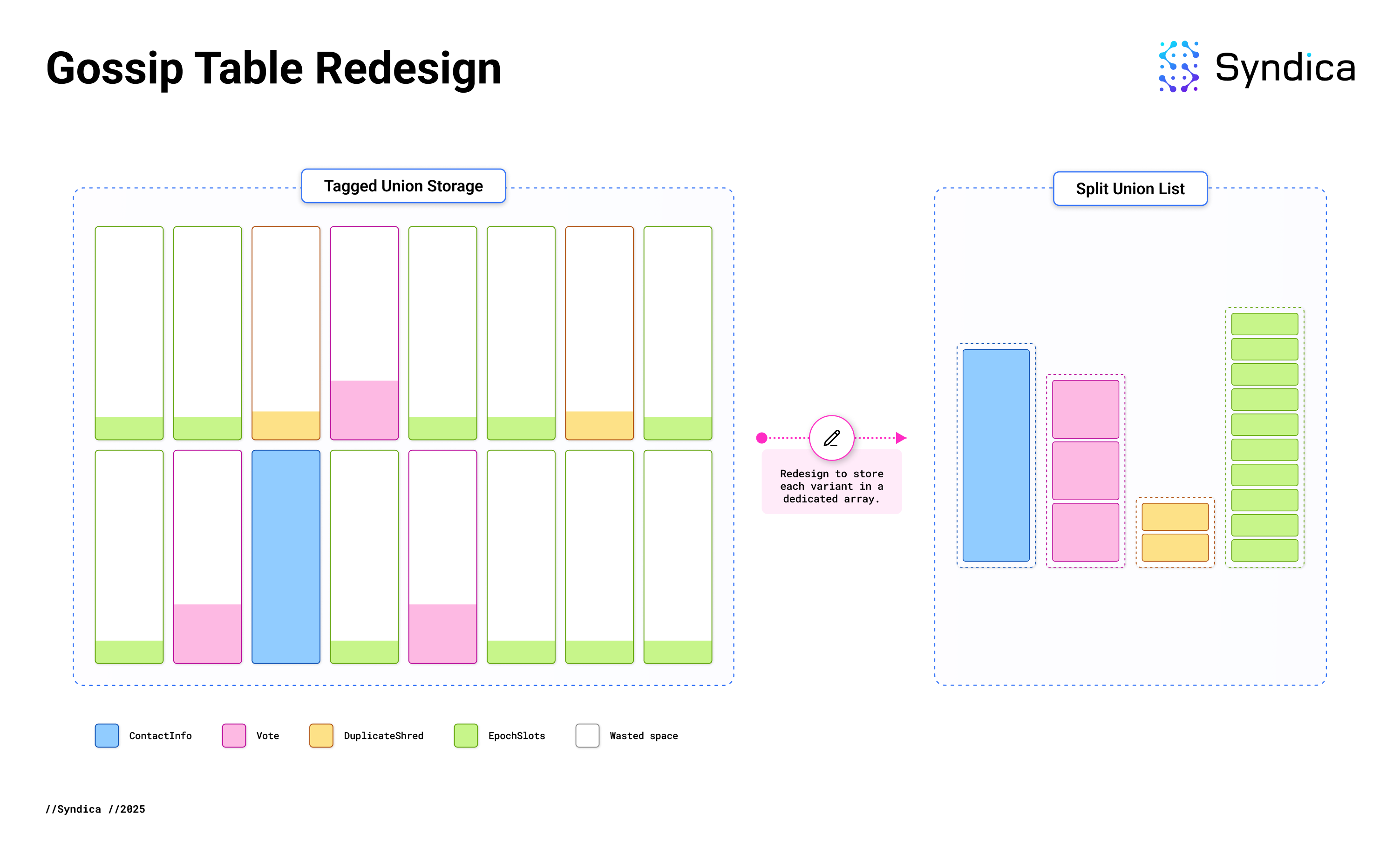
从概念上讲,修复很简单:与其将每个项目包装在 GossipData 中,我们不如直接存储内部变体,而无需标签联合。以前,有一个包含每个数据库条目的大型 GossipData 项目数组。现在,标签联合的每个变体都有自己的专用数组。
由于每个数组都专门用于特定的数据类型,因此我们在 编译时 知道存储每个项目所需的实际内存量。没有浪费内存在标签上或额外的空间来容纳更大的项目。这已将 Gossip Table 内存使用率降低了 80%。
内存布局以前看起来像左侧图像,但现在更像右侧图像。
 🔍 点击图片放大
🔍 点击图片放大
这是面向数据的设计的应用,这是一种基于内存布局组织代码的编程技术,对于 Solana 验证器等性能关键型、数据密集型应用程序尤其有利。
由于存储标签联合集合是一种常见的模式,在 Sig 中还有其他示例,因此我们开发了一种通用的数据结构 SplitUnionList,以简化和概括这种优化。
SplitUnionList
SplitUnionList 是专为有效存储标签联合而设计的通用列表类型。它具有与 ArrayList 类似的 API,使其成为方便的替代品。作为通用类型,SplitUnionList 可以配置为存储任何标签联合。保存 GossipData 实例的具体版本是 SplitUnionList(GossipData)。
在内部,SplitUnionList 为配置为存储的标签联合的每个变体包含一个单独的数组。如果显式写出 SplitUnionList(GossipData),它将如下所示:
pub const GossipDataSplitUnionList = struct {
LegacyContactInfo: ArrayListUnmanaged(LegacyContactInfo),
Vote: ArrayListUnmanaged(struct { u8, Vote }),
LowestSlot: ArrayListUnmanaged(struct { u8, LowestSlot }),
LegacySnapshotHashes: ArrayListUnmanaged(LegacySnapshotHashes),
AccountsHashes: ArrayListUnmanaged(AccountsHashes),
EpochSlots: ArrayListUnmanaged(struct { u8, EpochSlots }),
LegacyVersion: ArrayListUnmanaged(LegacyVersion),
Version: ArrayListUnmanaged(Version),
NodeInstance: ArrayListUnmanaged(NodeInstance),
DuplicateShred: ArrayListUnmanaged(struct { u16, DuplicateShred }),
SnapshotHashes: ArrayListUnmanaged(SnapshotHashes),
ContactInfo: ArrayListUnmanaged(ContactInfo),
RestartLastVotedForkSlots: ArrayListUnmanaged(RestartLastVotedForkSlots),
RestartHeaviestFork: ArrayListUnmanaged(RestartHeaviestFork),
};
然而,这种显式形式不是必需的。SplitUnionList 的字段在编译代码时会自动从标签联合生成。在大多数语言中,这是不可能的,或者需要复杂的宏,但 Zig 通过允许在编译时操作类型(就像普通数据一样)使其变得容易。
具体来说,SplitUnionList 是使用 EnumStruct 函数实现的。它接受两个输入:表示联合标签的枚举类型和从每个变体生成字段类型的函数。
pub fn EnumStruct(comptime E: type, comptime Data: fn (E) type) type {
@setEvalBranchQuota(@typeInfo(E).Enum.fields.len);
// Initialize an array for the struct fields.
var struct_fields: [@typeInfo(E).Enum.fields.len]StructField = undefined;
// Iterate over each enum variant.
for (&struct_fields, @typeInfo(E).Enum.fields) |*struct_field, enum_field| {
// Determine the type to use for the
// field derived from this variant.
const T = Data(@field(E, enum_field.name));
// Add a field to the array of struct fields,
// using the same name as the enum variant,
// and the type that was calculated above.
struct_field.* = .{
.name = enum_field.name,
.type = T,
.default_value = null,
.is_comptime = false,
.alignment = @alignOf(T),
};
}
// Generate and return a struct that contains
// the newly created fields.
return @Type(.{ .Struct = .{
.layout = .auto,
.fields = &struct_fields,
.decls = &.{},
.is_tuple = false,
} });
}
SplitUnionList 通过调用 EnumStruct 并传入两个参数来定义:联合的标签和将每个变体映射到其对应的 ArrayListUnmanaged 的函数。
pub fn SplitUnionList(TaggedUnion: type) type {
// Derive the tag from the tagged union (i.e. GossipDataTag).
const Tag = @typeInfo(TaggedUnion).Union.tag_type.?;
return struct {
// The struct where each tag corresponds to a field with an ArrayList.
lists: sig.utils.types.EnumStruct(Tag, List),
};
}
GossipMap
虽然 SplitUnionList 的行为类似于列表,但我们需要类似映射的 API 来支持 get 和 put 操作 为了实现这一点,我们实现了 GossipMap 结构。
GossipTable 最初是使用标准库中的哈希图实现的:
pub const GossipTable = struct {
store: AutoArrayHashMap(GossipKey, GossipVersionedValue),
...
现在它包含 GossipMap 来代替:
pub const GossipTable = struct {
store: GossipMap,
...
虽然 AutoArrayHashMap 由单个数组支持,但 GossipMap 是由 SplitUnionList 支持的具有类似 API 的哈希图,它将每个联合变体存储在单独的数组中。
请注意,存储中的值具有 GossipVersionedValue 类型,这是一个包含 GossipData 以及其他特定于 Gossip 的元数据的结构(而不是标签联合)。为了有效地处理这些元数据,GossipMap 需要自定义逻辑而不是通用方法。具体来说,GossipMap 将元数据与 GossipData 分开存储。这优化了内存访问模式,因为元数据和 GossipData 通常是独立访问的。
pub const GossipMap = struct {
key_to_index: AutoArrayHashMapUnmanaged(GossipKey, SplitUnionList(GossipData).Index),
gossip_data: SplitUnionList(GossipData),
metadata: ArrayListUnmanaged(Metadata),
};
采用 SplitUnionList 已将 Gossip Table 的内存使用率降低了 80%。此外,它还通过改善缓存局部性和降低内存带宽要求来解锁更快的内存访问。这个面向数据的设计案例研究产生了一种广泛适用的解决方案,用于在性能关键型应用程序中有效地存储标签联合。
结论
在这篇博文中,我们讨论了最近在 Sig 中所做的一些内存改进。我们从头开始实现了一个缓冲池,从而显式控制了 AccountsDB 中的内存使用率。我们还为标签联合实现了一种更有效的存储方法,消除了 Gossip 中的内存浪费。
当我们继续构建 Sig 时,设计一个内存高效的验证器是我们的主要目标之一。我们希望这篇文章可以激发对验证器内存使用率的讨论,并且很高兴分享我们在未来的博文中进行的其他优化。
- 原文链接: blog.syndica.io/sig-engi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 10
- 分类: Solana
- 标签: Solana AccountsDB gossip mmap Buffer Pool 内存优化





