Sig工程 - 第五部分 - Sig账本和区块存储
- syndica
- 发布于 2025-01-09 13:28
- 阅读 1388
本文是Sig工程更新系列文章的第五部分,主要介绍了Sig验证器中账本的实现以及如何针对模块化、灵活性和性能对其进行优化。文章详细解析了Sig账本的核心组件,讨论了如何设计它以支持多个数据库后端,并阐述了插入shred和读取交易等关键操作。
这篇文章是我们定期发布的,概述 Sig 工程更新的系列博客文章的第五部分。你可以在这里找到其他 Sig 工程文章。
在上一篇文章中,我们介绍了 Solana 的账本和 Blockstore 的结构与目的。理解这些背景知识对于深入了解 Sig 的账本是必要的。
在那个基础之上,本文探讨了我们如何在 Sig 验证器中实现账本,以及我们如何针对模块化、灵活性和性能对其进行优化。我们将分解 Sig 账本的核心组件,讨论我们如何设计它来支持多个数据库后端,并演练插入 Shreds 和读取交易等关键操作。
组件
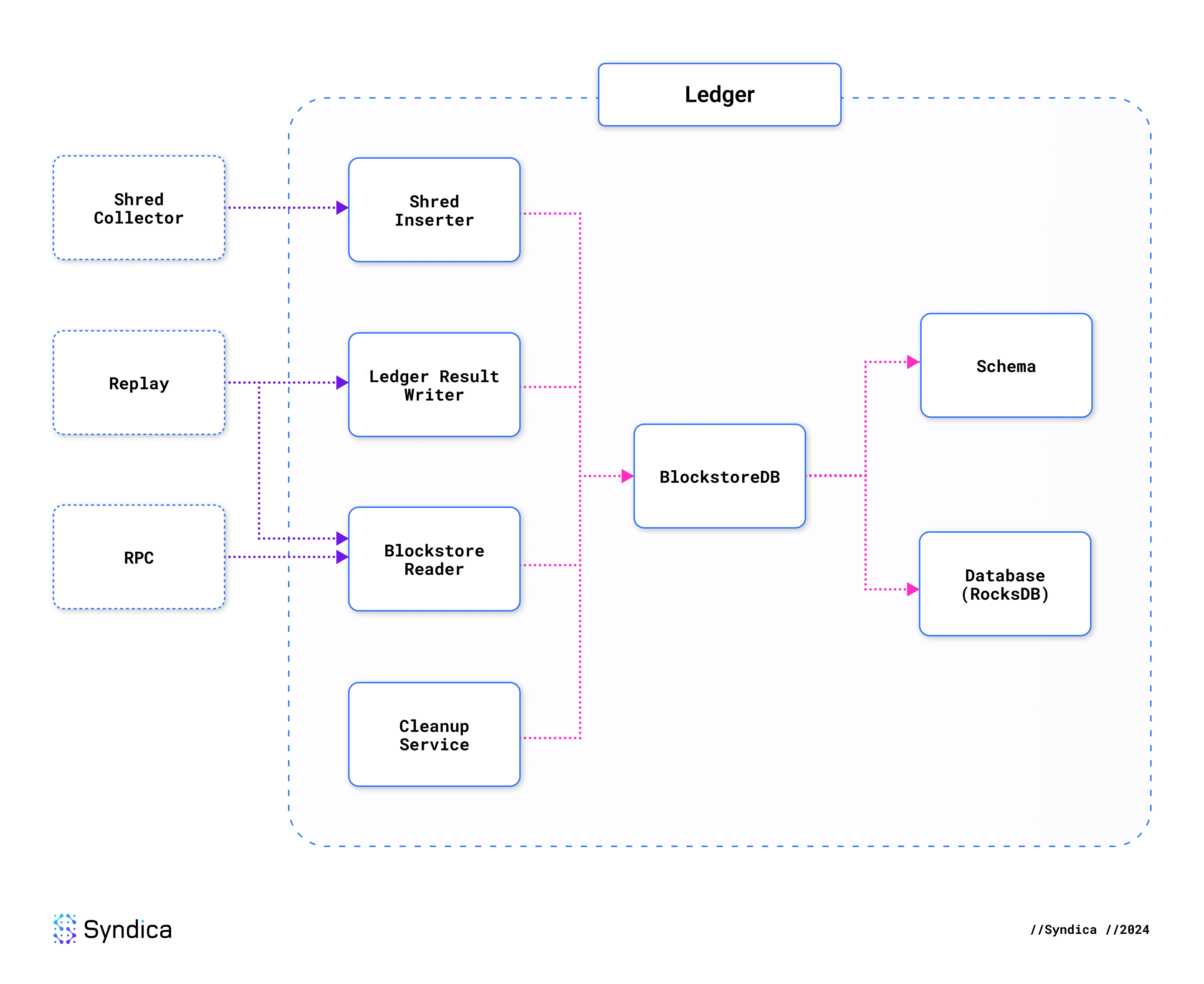
Sig 的账本采用模块化架构,以一个可插拔数据库为核心。专门的组件建立在这个数据库抽象之上,以处理特定的账本职责,从而产生一个灵活且可维护的系统。
默认情况下,Sig 的账本使用 RocksDB 进行存储(类似于 Agave)。但是,可插拔的后端允许使用任何任意数据库。Sig 目前支持三个不同的数据库,并且很容易添加对更多数据库的支持。
Shred Inserter(碎片插入器)、Blockstore Reader(区块存储读取器)和 Ledger Result Writer(账本结果写入器)构成了数据库之上的下一层。它们负责读取和写入数据库中所有数据的操作。这三个组件共同类似于 Agave 中的 Blockstore 结构体。
Sig 的账本由以下部分组成:
- 数据结构:
VersionedTransaction(版本化交易):账本中的一笔交易。Entry(条目):一个区块内的交易集合。Shred(碎片):代表数据碎片和代码碎片。Database(数据库):数据库抽象层,支持多种实现。BlockstoreDB:数据库实现和模式,目前使用 RocksDB。- Schema(模式):Blockstore 中包含的数据类型列表。
- 数据处理器:
- Shred Inserter(碎片插入器):验证、恢复并将碎片插入到数据库中。
- Ledger Result Writer(账本结果写入器):将重放和共识结果写入数据库。
- Blockstore Reader(区块存储读取器):用于从数据库中读取任何内容。
- Cleanup Service(清理服务):用于修剪旧的账本数据并限制存储使用。
下图显示了这些组件如何相互依赖。左侧的虚线框是一些依赖于账本的验证器组件的示例。
 🔍 点击图片放大
🔍 点击图片放大
数据结构
Sig 账本中的数据结构存储交易、区块和元数据。
VersionedTransaction
为了表示任何 Solana 交易,Sig 有一个名为 VersionedTransaction 的结构体。它包含一个密码签名列表和一个消息。
pub const VersionedTransaction = struct {
signatures: []const Signature,
message: VersionedMessage,
};消息可以采用两种不同的格式:legacy(旧版)或较新的 v0 消息。我们使用一个标记联合来表示这一点,它表示必须存在这些变体之一。
pub const VersionedMessage = union(enum) {
legacy: Message,
v0: V0Message,
};旧版消息是原始 Solana Transaction 结构体中使用的传统 Message。它包含一个指令列表,描述如何执行交易,以及将由交易使用的帐户列表。
pub const Message = struct {
header: MessageHeader,
account_keys: []const Pubkey,
recent_blockhash: Hash,
instructions: []const CompiledInstruction,
};MessageHeader 指示交易需要多少个签名,以及哪些帐户允许被交易修改。
pub const MessageHeader = struct {
num_required_signatures: u8,
num_readonly_signed_accounts: u8,
num_readonly_unsigned_accounts: u8,
};每个指令指定需要调用哪个链上 program_id,该指令将使用哪些 accounts,以及将由程序解释以执行该指令的输入 data。
pub const CompiledInstruction = struct {
program_id_index: u8,
accounts: []const u8,
data: []const u8,
};较新的 V0Message 几乎与旧版消息相同,只是它包含一个名为 address_table_lookups 的额外信息。
pub const V0Message = struct {
header: MessageHeader,
account_keys: []const Pubkey,
recent_blockhash: Hash,
instructions: []const CompiledInstruction,
address_table_lookups: []const MessageAddressTableLookup,
};
旧版交易必须包含交易中涉及的每个帐户地址的完整列表,这限制了它们的灵活性,因为它们的大小限制为 1232 字节。地址查找表通过将帐户地址存储在链上来释放此约束。你无需在交易中容纳多个地址,而是可以引用单个查找表地址。Solana 运行时从表中检索必要的地址,使 DApp 开发人员能够为更广泛的用例构建更复杂的交易。
Entry
Entry 是一种数据结构,表示由领导者捆绑在一起并作为单个有凝聚力的单元在网络上分发的交易集合。条目构成了 Shreds 的基础,因为它们被捆绑到一个列表中,序列化为单个数据 Blob,然后分解为 Shreds,如之前的博文中所述。
除了交易列表之外,条目还包括其来自 Proof-of-History 链的哈希值,以及自上一个条目以来链中发生的哈希数。
pub const Entry = struct {
num_hashes: u64,
hash: core.Hash,
transactions: std.ArrayListUnmanaged(core.VersionedTransaction),
};Shred
Shreds 有两种不同的类型:数据 Shreds 和代码 Shreds。Shred 中保存的主要数据是代表 Shreds 派生的条目的一部分的大量字节块。数据 Shreds 直接从序列化条目中保存实际数据,而代码 Shreds 保存可用于恢复丢失数据的 Reed-Solomon 纠删码。在任何一种情况下,数据类型都是相同的;它只是一个名为 fragment(片段) 的大字节块。
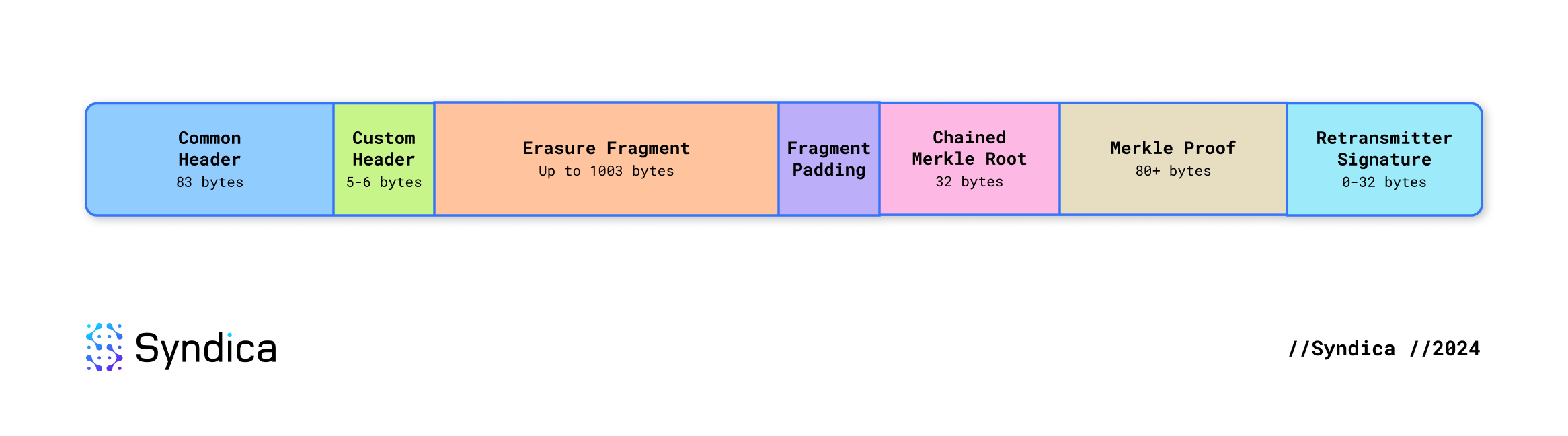
虽然为 Shreds 分配了 1228 个字节,但数据 Shreds 被任意限制在这些字节的 1203 个字节内。在为元数据留出空间后,这意味着擦除片段不能超过 1003 个字节。Shred 的二进制布局如下:
- Common Header(通用标头):83 字节
- Custom Header(自定义标头):5 字节(数据 Shred)或 6 字节(代码 Shred)
- Erasure Fragment(擦除片段):最多 1003 字节。这是可以在最小元数据量下容纳的最大片段。
- Padding(填充):如果片段小于最大值,则此处将有未使用的字节。
- Chained Merkle Root(链接的 Merkle 根):32 字节
- Merkle Proof(Merkle 证明):至少 80 字节。每个 Merkle 节点为 20 字节,并且你至少需要 4 层才能表示 18 个 Shreds - 最小的擦除集。
- Retransmitter Signature(重传器签名):0-32 字节(仅包含在最后一个擦除集中)
 🔍 点击图片放大
🔍 点击图片放大
由于数据 Shreds 和代码 Shreds 各自包含略有不同的元数据类型,因此每个 Shred 在代码中都用不同的数据类型表示:DataShred 和 CodeShred。
为了通用地表示任何 Shred 类型,我们将 Shred 定义为一个带标记的联合(在某些语言中也称为“枚举”),其中包含两个变体。
pub const Shred = union(ShredType) {
code: CodeShred,
data: DataShred,
};DataShred 和 CodeShred 都是包含字段集合的结构体。虽然存在一些关键差异,但高级结构是相似的。某些字段被数据 Shreds 和代码 Shreds 共同使用(CommonHeader),某些字段特定于不同类型的 Shreds(DataHeader 和 CodeHeader),并且 payload 是表示整个 Shred 的整个字节块(包括序列化标头)。
pub const DataShred = struct {
common: CommonHeader,
custom: DataHeader,
allocator: Allocator,
payload: []u8,
};
pub const CodeShred = struct {
common: CommonHeader,
custom: CodeHeader,
allocator: Allocator,
payload: []u8,
};通用字段
CommonHeader 是每个 Shred 中都存在的元数据。它包含领导者的签名,必须在处理 Shred 之前进行验证。variant(变体)字段将 Shred 定义为数据 Shred 或代码 Shred,以及一些相关的元数据。它还指定 Shred 的槽及其在槽的 Shred 序列中的唯一数值索引。version(版本)标识 Shred 来自的分叉。erasure_set_index 标识 Shred 所属的擦除集,它等于该集中第一个 Shred 的索引。
pub const CommonHeader = struct {
leader_signature: Signature,
variant: ShredVariant,
slot: Slot,
index: u32,
version: u16,
erasure_set_index: u32,
};数据字段
DataHeader 是数据 Shreds 中使用的自定义标头。
pub const DataHeader = struct {
parent_slot_offset: u16,
flags: ShredFlags,
size: u16,
};parent_slot_offset 指示此 Shred 的父槽是哪个槽(parent_slot = slot - parent_slot_offset)。如果父偏移量大于 1,则跳过了上一个槽。当跳过一个槽时,这意味着该槽的链中不包含任何区块。跳过槽的一个原因是该槽的领导者未能生成区块。在这种情况下,下一个槽的领导者必须指定其父槽是 2 个槽之前的区块。
flags 指示当前 Shred 是否是擦除集或槽的最终 Shred。它还包括一个参考时间片,以指示何时创建擦除集。
size 告诉我们标头和片段组合使用了多少空间。它用于从 Shred 中提取擦除片段。
代码字段
CodeHeader 是代码 Shreds 的自定义标头。这指示了擦除集中要预期的数据 Shreds 和代码 Shreds 的总数,以及代码 Shred 在该集中其他代码 Shreds 中的索引。
pub const CodeHeader = struct {
num_data_shreds: u16,
num_code_shreds: u16,
erasure_code_index: u16,
};其他数据
这些是 Shred 结构体中唯一存在的字段。其余数据仅存在于 Shred payload(定义为字节数组)中,可以使用特定方法按需提取。
标头之后是 erasure fragment(擦除片段)。这与其他 Shreds 中擦除集的片段结合在一起,以重建条目集合。
接下来是 chained Merkle root(链接的 Merkle 根)。这是先前擦除集的 Merkle 根。它用于验证领导者是否生成了擦除集的线性序列。
接下来是 Merkle proof(Merkle 证明)。它证明当前 Shred 是为擦除集构建的 Merkle 树的一部分。Merkle root(Merkle 根) 未直接包含在 Shred 中。它通过以递归方式将 Shred 片段与证明中的哈希值进行哈希计算来计算。
最后,retransmitter signature(重传器签名) 由通过 Turbine 将 Shred 重新传输给我们的节点添加。这仅用于槽的最终擦除集中的 Shreds。
Database
Database 是 Sig 中的一个 interface(接口),它定义了键值存储的概念。它不实现任何特定的数据库。它只定义了一个抽象,使 Sig 能够连接到任何数据库。
通过这种抽象,Sig 可以与任何任意数据库后端一起使用。目前,Sig 支持三个后端:RocksDB、LMDB 和哈希映射。数据库后端使用 blockstore 构建选项选择。例如,此命令使用 LMDB 作为数据库构建 Sig。
zig build -Dblockstore=lmdb接口 是一组商定的规则或蓝图,用于指定程序的不同部分如何在不描述这些部分内部工作方式的情况下进行交互。通过指定可用的操作,但不指定如何执行这些操作,接口允许我们编写模块化和灵活的代码。这使程序可以与遵守相同接口的各种系统或组件(如不同的文件系统或数据库)一起使用,而无需更改核心代码。这种方法简化了开发,提高了代码的可读性,并有助于未来的更新。
对于数据库,我们需要支持许多操作。主要操作有:
put:将数据保存到数据库中get:从数据库加载数据delete:从数据库中删除数据
数据库是一个键值存储。当你把数据 put 到数据库中时,你需要提供一个键和一个值。值 是你想存储的数据,键 是用于定位该值的标签。当你从数据库中 get 出数据的时候,你需要指定一个键,数据库会使用这个键来定位这个值,然后数据库会把这个值作为输出提供出来。
列族
在一个数据库中,有许多叫做 column families(列族) 的部分。一个列族就是一个单独的键值存储。它类似于关系型数据库中的表。
ColumnFamily 是 Sig 中的一个数据类型。它指定了列族的名字,以及我们期望在数据库中该列族找到的信息的类型。
pub const ColumnFamily = struct {
name: []const u8,
Key: type,
Value: type,
};举个例子,假设你现在有一个叫做 "country populations(国家人口)" 的列族。键类型可以是一个 "string(字符串)",代表国家的名字,而值类型可以是一个 "integer(整数)",代表人口。这个列族可以像下面这样定义:
const country_pop_cf = ColumnFamily{
.name = "country populations,"
.Key = []const u8, // "[]const u8" 是 Zig 中表示 "string(字符串)" 的方式
.Value = u64, // u64 是一种整数类型
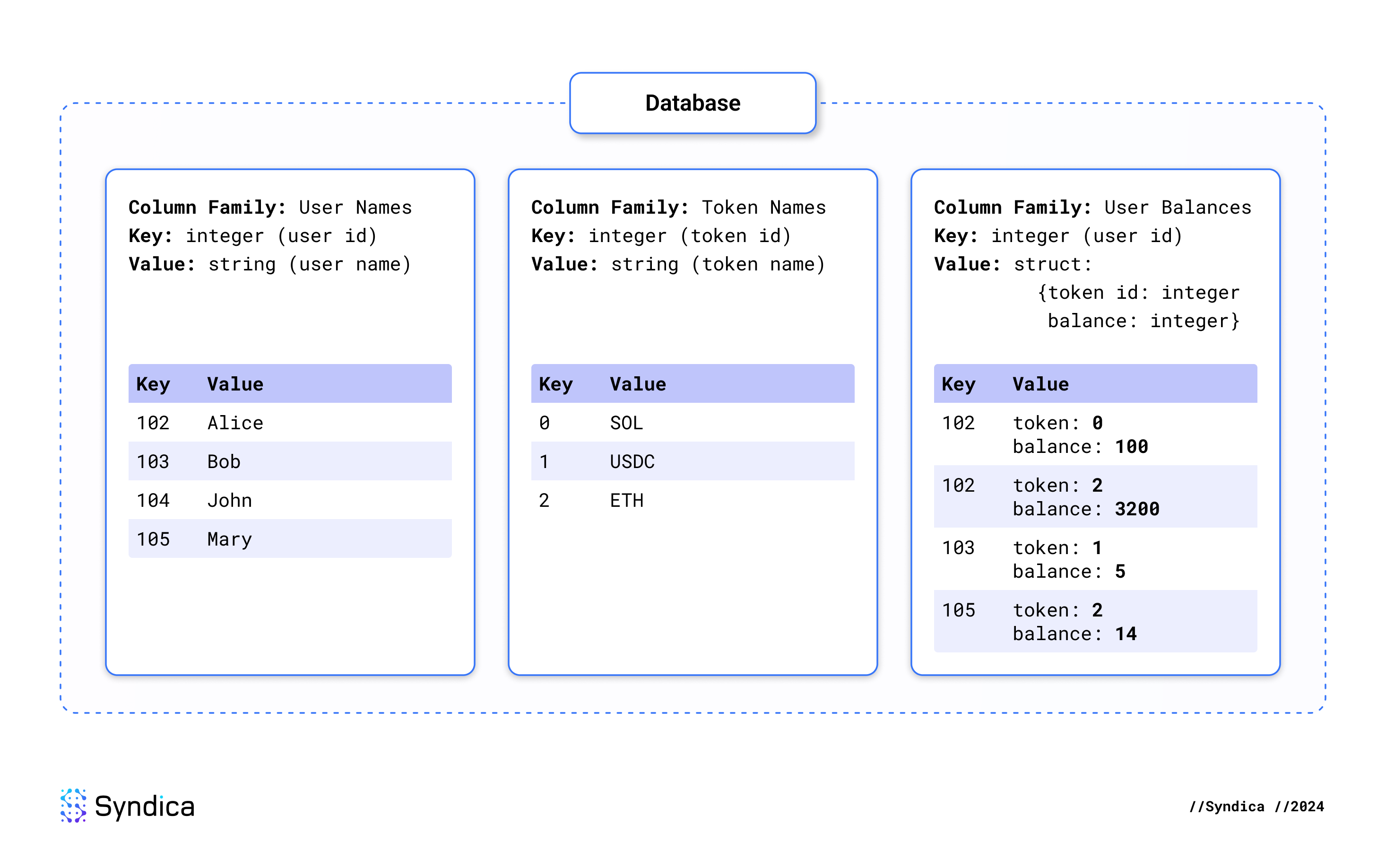
};这里是另一个例子,说明了如何使用包含多个列族的数据库。这个数据库标识了用户、token 和用户 token 余额。将所有列族中的数据连接起来,可以看到 Alice 拥有 100 SOL 和 3200 ETH 的余额,Bob 拥有 5 USDC 的余额,而 Mary 拥有 14 ETH 的余额。
 🔍 点击图片放大
🔍 点击图片放大
数据库定义
下面是 Database 如何定义三个核心操作:get、put 和 delete:
/// Interface defining the ledger's dependency on a database.
/// 定义账本对数据库的依赖关系的接口。
pub fn Database(comptime Impl: type) type {
return struct {
impl: Impl,
/// Save the provided key-value pair in the specified column family.
/// 将提供的键值对保存在指定的列族中。
pub fn put(
self: *Self,
comptime cf: ColumnFamily,
key: cf.Key,
value: cf.Value,
) anyerror!void {
return try self.impl.put(cf, key, value);
}
/// Load the value associated with the provided key from the specified column family.
/// 从指定的列族中加载与提供的键关联的值。
pub fn get(
self: *Self,
allocator: Allocator,
comptime cf: ColumnFamily,
key: cf.Key,
) anyerror!?cf.Value {
return try self.impl.get(allocator, cf, key);
}
/// Delete the value associated with the provided key from the specified column family.
/// 从指定的列族中删除与提供的键关联的值。
pub fn delete(self: *Self, comptime cf: ColumnFamily, key: cf.Key) anyerror!void {
return try self.impl.delete(cf, key);
}
};
}让我们专注于以 pub fn get 开头的代码区域。这是接口描述的 get 操作的定义。这些是输入和输出:
- 输入:
self: *Self:这意味着该操作需要数据库。allocator: Allocator:这是 Zig 的一个底层特性。它使调用者能够定义函数应如何从操作系统访问内存。Zig 的这个强大功能使我们能够以 Rust 和 C 等语言无法轻松支持的方式直接控制程序的性能。cf: ColumnFamily:数据库包含许多列族,因此我们必须具体说明要从中获取数据的列族。key: cf.Key:这是键值对中的键。通过将其传递到get函数中,我们要求数据库在指定的列族中查找与此键关联的值。它的类型是cf.Key,这意味着它是在列族中指定为键类型的类型。此处提供的类型必须符合列族期望的类型。
- 输出: 输出是类型为
anyerror!?cf.Value的单个数据。此类型很复杂,但它的含义是该函数有三种不同的输出选择。让我们按每个部分进行分解。anyerror!:这意味着该函数可能会出错。例如,如果删除数据库文件,它将返回一个错误。?:这表示输出可能为 null。这意味着数据库无法在数据库中找到该键。cf.Value:这意味着该函数可以返回类型指定为列族的“值”类型的数据。如果返回此数据,则表示在数据库中找到了该键,并且该函数正在输出我们正在寻找的关联值。
你可能已经注意到 Database 不仅仅是一个结构体;它实际上是一个函数,它将 type 作为其输出返回。这就是 Sig 允许插入多个后端实现而不更改核心账本代码的方式。
pub fn Database(comptime Impl: type) type {
return struct { ... };
}这意味着 Database 是一个泛型类型。泛型类型是在 Zig 中实现接口模式的一种方式。Database 的潜在变体数量不受限制,这些变体在技术上都是不同的类型。Database 定义了一组行为,可以使用任何任意实现类型(Impl)。你可以将具体的数据库实例描述为具有 Database(RocksDB) 之类的类型。
Database 只是将所有操作委托给 Impl 字段。每个函数体看起来都像这样:
return try self.impl.put(cf, key, value);这意味着 Impl 类型应实现 Database 定义的同一组行为。例如,Database(RocksDB) 在底层使用 RocksDB 来实现所有操作。
数据库实现:RocksDB
RocksDB 是 Facebook 用 C++ 实现的键值存储。它是 Agave 中用于 Blockstore 的数据库,我们也支持它在 Sig 中使用。
zig build -Dblockstore=rocksdbRocksDB 是一个库。它不是一个单独的应用程序,我们不会单独运行它,而是通过网络连接到它。我们的应用程序需要通过将它的代码作为 Sig 的一部分直接使用它。RocksDB 是用 C++ 实现的,这与 Agave 或 Sig 的语言不同。那么,每个项目是如何集成它的呢?
在 Agave 中,RocksDB 与 rocksdb crate 集成。这是一个预先存在的 Rust 库,它与 C++ 库集成。在底层,该 crate 包含一个 build.rs 脚本,用于使用 C++ 编译器 Clang 构建 RocksDB,在构建该库之前,必须在主机系统上安装 Clang。这给构建过程带来了复杂性,并限制了依赖它的 Rust 程序的灵活性。
Zig RocksDB 库
对于 Sig,我们无法使用 Zig 中实现的现有 RocksDB 库。以前有一些尝试,但没有一个能满足我们的需求。但是,Zig 可以轻松地直接使用 Zig 编译器构建和集成 C 和 C++ 项目。因此,我们编写了自己的 Zig 库,名为 rocksdb-zig。与 Sig 一样,rocksdb-zig 也是开源的。我们鼓励你将它用于你的项目,并且我们乐于接受贡献。
由于我们使用的是 Zig,因此我们不需要依赖任何外部编译器。Zig 本身 就是一个 C 和 C++ 编译器。构建过程在 build.zig 中实现。下面是创建名为 rocksdb 的 Zig 库的关键代码行,该库包含 RocksDB 项目中的 C++ 源文件:
const librocksdb_a = b.addStaticLibrary(.{ .name = "rocksdb" };
librocksdb_a.addCSourceFiles(.{
// list of c++ files from RocksDB
// RocksDB 中的 C++ 文件列表
});
b.installArtifact(librocksdb_a);这可以作为普通的 Zig 依赖项导入。下面是如何使用两个列族打开 RocksDB 数据库:
const rdb = @import("rocksdb");
// set up arguments
// 设置参数
const path = "/path/to/db";
const cf_names: [2][]const u8 = .{
"default",
"other cf",
};
const cf_options: [2]?*const rdb.rocksdb_options_t = .{
rdb.rocksdb_options_create().?,
rdb.rocksdb_options_create().?,
};
const cf_handles: [2]?*rdb.rocksdb_column_family_handle_t = .{ null, null };
const maybe_err_str: ?[*:0]u8 = null;
// open database
// 打开数据库
const database = rdb.rocksdb_open_column_families(
db_options.convert(),
path.ptr,
@intCast(cf_names.len),
@ptrCast(cf_names[0..].ptr),
@ptrCast(cf_options[0..].ptr),
@ptrCast(cf_handles[0..].ptr),
&maybe_err_str,
);
// handle errors
// 处理错误
if (maybe_err_str) |error_str| {
return error.RocksDBOpen;
}由于这直接调用 C 代码,因此你需要使用 RocksDB 的 C API 固有的某些笨拙的编程模式。例如:
- 你需要将许多额外的参数传递给通常由现代语言中的结构体或返回值处理的函数。
- 你需要使用 C 指针而不是 Zig 切片,后者不太安全。
- 结构体是不透明的,需要使用 getter 和 setter 才能访问其状态。
- API 中的每个名称都多余地以
rocksdb_开头。
这就是为什么我们用 Zig 编写了自己的惯用 bindings(绑定) 库的原因。你可以在 src 文件夹中找到它。我们的库使用更用户友好的 Zig API 包装了 RocksDB 的 C API,并充分利用了 Zig 的现代语言功能。下面是如何使用绑定库完成与上面的示例相同的事情:
const rocks = @import("rocksdb-bindings");
const col_fams = .{
.{ .name = "default" },
.{ .name = "other cf" },
};
const database, _ = try rocks.DB.open(allocator, "/path/to/db", .{}, col_fams, &null);rocksdb-zig 提供以下 Zig 库:
rocksdb用于直接访问 RocksDB C APIrocksdb-bindings用于 Zig API
Sig 中的 RocksDB 数据库
使用 RocksDB 作为 Blockstore 数据库非常简单。我们只需要定义一个结构体来实现 Database 中的必需方法。Sig 中的这个结构体称为 RocksDB。大部分工作是通过委托给 rocksdb-zig 中的 rocks.DB 来处理的,但它也有自己的一些职责:
- 序列化在 Sig 数据类型和 RocksDB 存储的原始字节之间进行转换
- 从 Blockstore 模式中使用的
ColumnFamily描述映射到 RocksDB 内部用于标识列族的ColumnFamilyHandle - 记录错误
下面是 put 方法如何使用 rocksdb-bindings 库:
const rocks = @import("rocksdb-bindings");
pub fn RocksDB(comptime column_families: []const ColumnFamily) type {
return struct {
allocator: Allocator,
db: rocks.DB,
logger: Logger,
cf_handles: []const rocks.ColumnFamilyHandle,
path: []const u8,
pub fn put(
self: *Self,
comptime cf: ColumnFamily,
key: cf.Key,
value: cf.Value,
) anyerror!void {
const key_bytes = try key_serializer.serializeToRef(self.allocator, key);
defer key_bytes.deinit();
const val_bytes = try value_serializer.serializeToRef(self.allocator, value);
defer val_bytes.deinit();
return try callRocks(
self.logger,
rocks.DB.put,
.{
&self.db,
self.cf_handles[cf.find(column_families)],
key_bytes.data,
val_bytes.data,
},
);
}
};
}数据库实现:LMDB
LMDB 是 RocksDB 的一种轻量级替代方案,用 C 实现。与 RocksDB 一样,我们使用 Zig 构建系统构建 LMDB。lmdb-zig 完全开源,你可以轻松地将其直接导入到 Zig 项目中。LMDB 轻于 RocksDB,并且对于某些工作负载,LMDB 的性能更好。我们的目标是在未来的性能优化中利用这一点。
zig build -Dblockstore=lmdb下面是我们的 LMDB 数据库实现中 put 函数的示例。你可以看到我们直接使用 LMDB C 库实现了它。
pub fn LMDB(comptime column_families: []const ColumnFamily) type {
return struct {
allocator: Allocator,
env: *c.MDB_env,
dbis: []const c.MDB_dbi,
path: []const u8,
const Self = @This();
pub fn put(
self: *Self,
comptime cf: ColumnFamily,
key: cf.Key,
value: cf.Value,
) anyerror!void {
const key_bytes = try key_serializer.serializeToRef(self.allocator, key);
defer key_bytes.deinit();
const val_bytes = try value_serializer.serializeToRef(self.allocator, value);
defer val_bytes.deinit();
const txn = try ret(c.mdb_txn_begin, .{ self.env, null, 0 });
errdefer c.mdb_txn_abort(txn);
var key_val = toVal(key_bytes.data);
var val_val = toVal(val_bytes.data);
try result(c.mdb_put(txn, self.dbi(cf), &key_val, &val_val, 0));
try result(c.mdb_txn_commit(txn));
}
};
}数据库实现:Hash Map DB
我们还使用哈希映射在纯 Zig 中实现了一个数据库。整个实现有 500 行 Zig 代码,没有依赖项。它使用普通的哈希映射,并使用磁盘支持的 allocator 将它们写入磁盘。Zig 灵活的 Allocator 接口使这种设计成为可能。哈希映射数据库是一个基本的概念验证,不打算符合 ACID 标准,但它足以支持一个功能性的账本。此数据库非常轻量级并减少了外部依赖项,这使其对于测试或运行轻客户端非常有用。在我们的基准测试中,它的性能与 RocksDB 相似。
zig build -Dblockstore=hashmap下面是 SharedHashMapDB 中的 put 如何工作:
pub fn SharedHashMapDB(comptime column_families: []const ColumnFamily) type {
return struct {
/// For small amounts of metadata or ephemeral state.
/// 用于少量元数据或临时状态。
fast_allocator: Allocator,
/// For database storage.
/// 用于数据库存储。
storage_allocator: Allocator,
/// Implementation for storage_allocator
/// 用于 storage_allocator 的实现
batch_allocator_state: *BatchAllocator,
/// Backing allocator for the batch allocator
/// 用于批处理分配器的支持分配器
disk_allocator_state: *DiskMemoryAllocator,
/// Database state: one map per column family
/// 数据库状态:每个列族一个映射
maps: []SharedHashMap,
/// shared lock is required to call locking map methods.
/// 调用锁定映射方法需要共享锁。
/// exclusive lock is required to call non-locking map methods.
/// 调用非锁定映射方法需要互斥锁。
/// to avoid deadlocks, always acquire the shared lock *before* acquiring the map lock.
/// 为了避免死锁,始终在获取映射锁 *之前* 获取共享锁。
transaction_lock: *RwLock,
const Self = @This();
pub fn put(
self: *Self,
comptime cf: ColumnFamily,
key: cf.Key,
value: cf.Value,
) anyerror!void {
const key_bytes = try key_serializer.serializeAlloc(self.storage_allocator, key);
errdefer self.storage_allocator.free(key_bytes);
const val_bytes = try serializeValue(self.storage_allocator, value);
errdefer val_bytes.deinit(self.storage_allocator);
self.transaction_lock.lockShared();
defer self.transaction_lock.unlockShared();
return try self.maps[cf.find(column_families)].put(key_bytes, val_bytes);
}
};
}
const SharedHashMap = struct {
allocator: Allocator,
map: SortedMap([]我们保证接口通过 `assertIsDatabase` 函数得到正确实现,该函数在编译时运行。这意味着除非 `BlockstoreDB` 实现了 `Database` 接口,否则应用程序将不会编译。
```zig
test BlockstoreDB {
ledger.database.assertIsDatabase(BlockstoreDB);
}assertIsDatabase 由 Sig 中定义的泛型函数 assertImplements 提供支持。在这个函数中,我们用 Zig 编写了一个新颖的接口模式实现,它可以用来强制执行任何接口。
数据处理器
数据处理器是负责执行账本核心操作的组件:插入 shreds、读取数据和写入交易结果。这些是模块化组件,反映了 Agave 中 Blockstore 结构中实现的行为集。
Shred 插入器
当新的 shreds 从网络到达时,我们必须将它们插入到数据库中,以保持账本的更新。这是 Shred 插入器的唯一职责,它只公开一个名为 insertShreds 的公共方法来执行整个过程。
插入 shreds 很复杂,因为我们需要在插入它们之前理解它们。我们需要不断监控关于 shreds 的元数据,对每个 shred 执行许多验证,并使用里德-所罗门纠删码重建丢失的 shreds。让我们逐步分解一下。
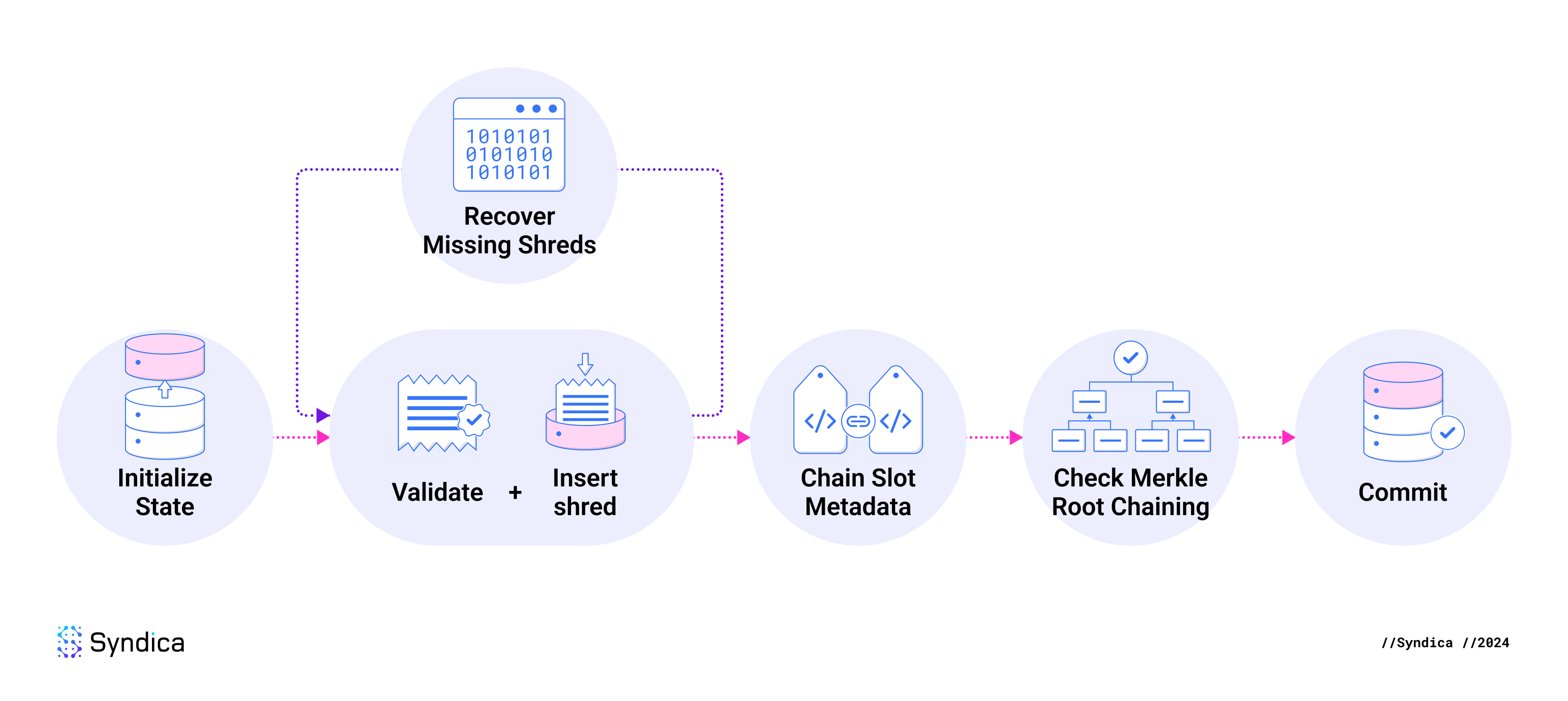
当插入 shreds 时,步骤如下:
- 初始化插入状态。
- 为每个 shred 运行 验证 + 插入 循环。
- 验证 shred。
- 将 shred 插入到挂起状态。
- 将元数据插入到挂起状态。
- 恢复丢失的 shreds。
- 通过重新运行 验证 + 插入 循环来插入恢复的 shreds。
- 链式 slot 元数据。
- 检查 Merkle 根链。
- 将挂起状态提交到数据库。
 🔍 点击图片放大
🔍 点击图片放大
Shred 插入数据库模式
在插入从网络接收到的 shreds 时,我们会跟踪关于这些 shreds 的各种类型的元数据。这些元数据被高级聚合,并针对每个 slot 或每个 erasure set 进行跟踪。这些元数据帮助我们了解我们是否收到了一个 slot 的所有 shreds (意味着我们有一个完整的块),或者我们是否可以恢复丢失的 shreds。它还帮助我们比较不同的 shreds,并确保它们都是一致的,以便它可以标记具有不一致数据的 slots。这些元数据存储在以下七个列族中:
Slot 元数据:
slot_meta: 关于 slot 的信息,包括我们收到了该 slot 的多少 shreds,以及我们是否处理了来自任何相邻 slots 的数据。index: 每个 slot 的统一数据结构,指示已收到该 slot 的哪些 shreds。dead_slots: 指示一个 slot 是否“死亡”。一个死亡的 slot 是 leader 已经降级为具有比最初计划更少的 shreds 的 slot。这意味着可能无法从这个 slot 中派生出一个完整的块。duplicate_slots: 指示 leader 是否为该 slot 生成了重复的块。如果 leader 犯了这个错误,则数据不能包含在账本中。orphan_slots: 跟踪我们已经收到 shreds 但没有收到其父 slots 的 shreds 的 slots。一个 slot 的父 slot 是应该紧随其后的 slot。
Erasure Set 元数据:
erasure_meta: 关于每个里德-所罗门 erasure set 的元数据,例如该集合中有多少 shreds。merkle_root_meta: 存储每个里德-所罗门 erasure set 的 Merkle 根及其来源的 shred。
初始化插入状态
Shred 插入必须是原子的:所有 shreds 及其元数据应该同时插入,或者都不能插入。
例如,一个列族跟踪 shreds,另一个列族跟踪它们的插入状态。如果这些变得不一致 (从更新它们的插入状态但不插入 shreds),数据库将被损坏,并且会发生许多错误。许多其他关系也需要像这样原子性。
为了确保这一点,我们使用称为 write batches 的原子数据库事务来写入数据库。像 RocksDB 和 LMDB 这样的数据库能够保证一系列更改以原子方式执行。
人们可能会认为,仅使用 write batches 的简单方法对于原子性来说是一个很好的解决方案。但是,这对于以下两个原因是不够的:
- 有些数据可能需要多次修改,需要重复的数据库插入,这是低效的。
- Shred 插入需要从数据库中读取最新的数据,但是由于新数据仅在 write batch 中,因此数据库视图变得陈旧。我们需要一种在查看数据库之前检查新数据的方法。
为了处理这个问题,我们创建了 PendingInsertShredsState 结构,它在 shred 插入期间充当数据库的代理。它跟踪实时更新,允许你随时读取最新状态,并且它生成无冗余的 write batches。你可以在 ledger/shred_inserter/working_state.zig 中找到这个结构。
验证-插入 循环
接下来的三个步骤对当前批次中的每个 shred 重复执行。验证并插入 shred,然后相应地更新元数据。
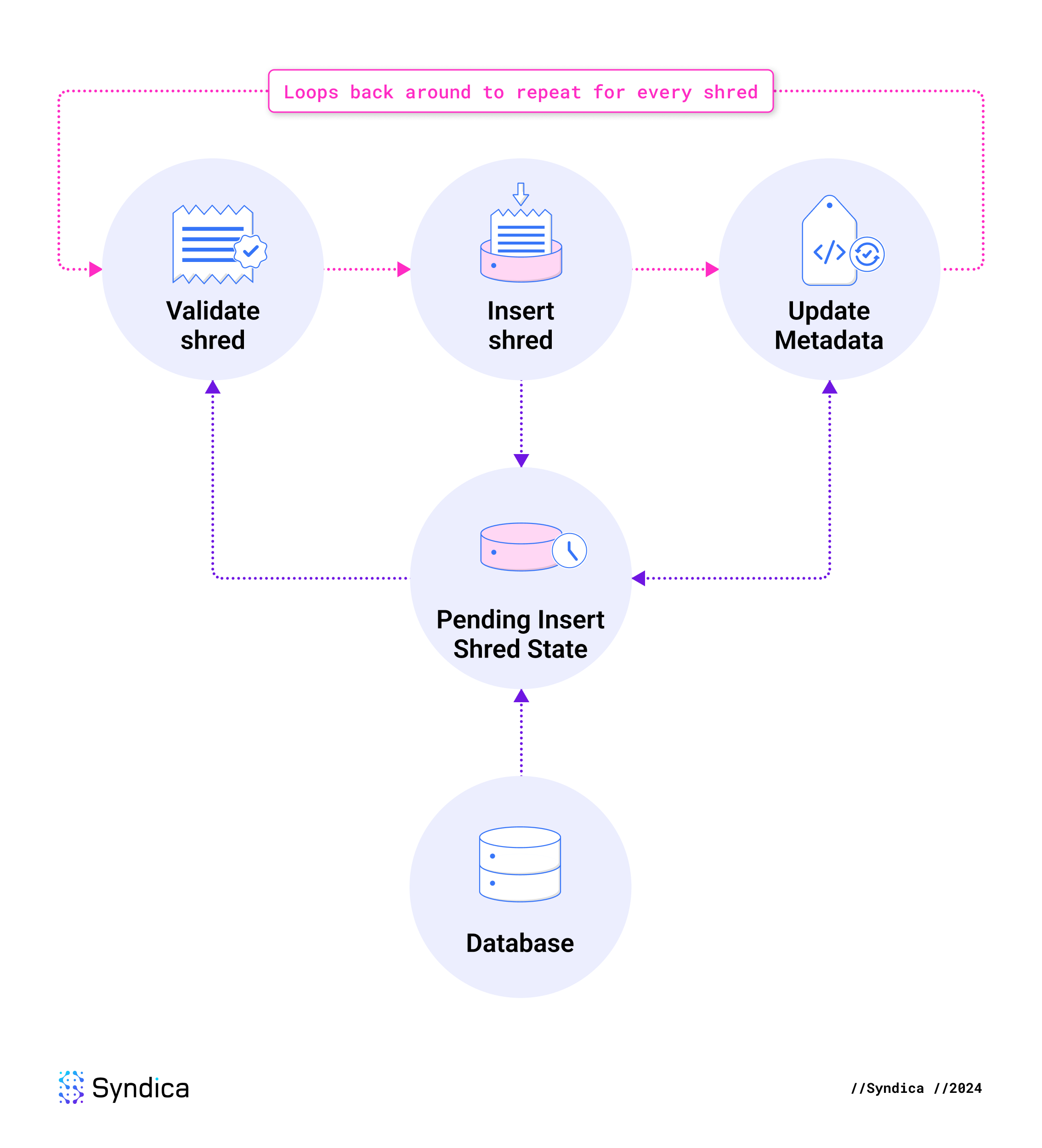 🔍 点击图片放大
🔍 点击图片放大
验证 shreds
为了确保对抗性网络中的拜占庭容错,我们不能信任我们收到的任何数据。我们必须在插入每个 shred 之前验证其有效性。如果未满足任何要求,则我们将丢弃该 shred。验证在 checkInsertCodeShred、checkInsertDataShred 和 shouldInsertDataShred 中实现。
对 所有 shreds 的要求:
- 整个 shred 必须符合有效的二进制布局。例如,如果 shred 的头部指示它包含一个重传器签名,则必须存在 32 个字节来表示该签名。
- shred 索引不得超过每个 slot 的最大 shred 数量:32,768。
- shred 必须是 erasure set 的 Merkle 树的一部分。这通过从 Merkle 证明中派生 Merkle 根并确保计算出的根等于为来自同一 erasure set 的先前接收到的 shreds 计算出的根来验证。
- 之前不得为这个 slot 和 shred 索引插入 shred。
- shred 的签名必须包含来自 Merkle 根的 leader 的有效签名。 (注意:此要求由 Shred Verifier 强制执行,它是 Sig 的一个单独组件,而不是 Shred Inserter。)
对 数据 shreds 的要求:
- 如果先前的 shred 说一个不同的 shred 将是最后一个,则该 shred 不得声称是 slot 中的最后一个。如果发生这种情况,我们还将 slot 标记为“死亡”,因为 leader 的行为不当,这意味着 slot 已损坏。
- shred 不得是“重复的”,这意味着满足以下条件之一。如果发现它是重复的,则 slot 已损坏,并且 shred 的 slot 保存在
duplicate_slots中。- shred 的索引大于先前 shred 已经声明为当前 slot 的最后一个索引的索引。
- shred 声称是 slot 中的最后一个索引,但我们收到了索引高于此索引的 shreds。
- shred 的父 slot 不得是…
- …大于此 shred 的 slot。这将是一个时间矛盾。
- …早于最高的 rooted slot。这意味着 shred 的 slot 应该已经被 rooted,所以我们不需要它。
对 代码 shreds 的要求:
- 头部中指定的代码 shreds 的数量必须小于 256。
- 必须可以计算 shred 的片段在 erasure set 中的有效位置。
- shred 不得来自 rooted slot。
- shred 上的 erasure 字段必须与从此 erasure set 收到的第一个 shred 中的字段一致。
插入接收到的 Shreds
一旦 shred 通过了所有完整性检查,它就会存储在 PendingInsertShredsState 中。这意味着我们向当前的 write batch 中添加了一个 put 指令,它们也存储在挂起状态变量中,在那里它们可以在当前的 insertShreds 操作中稍后访问。
💡
注意: 在数据库中插入一个块的 shreds 并不意味着该块已最终确定为区块链中的一个块。交易仍然需要验证,并且集群必须达成共识。插入 shreds 只是意味着这些 shreds 具有足够的完整性来存储在账本中并供其他验证器组件使用。
插入元数据
在跟踪验证后的 shreds 后,以下列族将更新(在挂起状态下)以记录我们从 shred 中获得的新信息:
index: 确认我们收到了这个 shred。slot_meta: shred 可能具有我们收到的最高索引,或者它可能告诉我们哪个索引是 slot 中的最后一个索引。无论哪种情况,都会更新 slot 的元数据。erasure_meta: 如果这是我们从 erasure set 收到的第一个代码 shred,则保存有关 erasure set 的元数据。merkle_root_meta: 如果这是我们从 erasure set 收到的第一个 shred,则保存 Merkle 根的哈希,并将这个 shred 标识为来源。
恢复 Shreds 并插入它们
在更新来自新收到的 shreds 的元数据后,下一步是尝试重建丢失的 shreds。
例如,假设一个 erasure set 包含 5 个数据 shreds,我们已经收到了 2 个数据和 2 个代码 shreds。从这个 erasure set 接收到任何新的 shred 都会给我们总共 5 个 shreds,这使我们能够重建完整的 erasure set。
为了确定我们是否可以恢复 shreds,我们首先检查 ErasureMeta 以了解需要多少 shreds 才能恢复整个 erasure set。
pub const ErasureMeta = struct {
/// Which erasure set in the slot this is
erasure_set_index: u64,
/// First code index in the erasure set
first_code_index: u64,
/// Index of the first received code shred in the erasure set
first_received_code_index: u64,
/// Erasure configuration for this erasure set
config: ErasureConfig,
};
pub const ErasureConfig = struct {
/// number of data shreds in the erasure set
num_data: usize,
/// number of code shreds in the erasure set
num_code: usize,
};然后,我们将其与我们收到的 shreds 数量进行比较。对于 erasure set 中的每个 shred,我们检查 Index 以查看是否已收到它。我们计算命中次数以确定从该集中收到的 shred 总数。
pub const Index = struct {
slot: Slot,
/// The indexes of every data shred received for the slot
data_index: Set(u64),
/// The indexes of every code shred received for the slot
code_index: Set(u64),
};如果我们有足够的 shreds 来重建整个集合,我们就可以从挂起状态收集可用的 shreds,或者如果该 shred 不存在于其状态中,则从数据库读取。
来自 shreds 的 erasure 片段被传递到 ReedSolomon.reconstruct,我们在其中用 Zig 实现了里德-所罗门纠错算法。此函数输出来自 erasure set 的所有 shreds 的完整集合。
由于里德-所罗门算法中涉及的数字庞大(每个片段约为 1 KB,或十进制形式,一个约有 3,000 位的数字),因此我们之前的博客文章中描述的拉格朗日插值过程被重新构建为有限域上的矩阵运算,以使该过程更适合计算机高效执行。
在重建丢失的 shreds 后,它们以与我们通过网络接收到的 shreds 相同的方式进行验证和插入。
链式 slot 元数据
为了组织有关每个 slot 的信息,我们使用 slot_meta 列族,该列族将 slot 编号映射到 SlotMeta:
/// The slot_meta column family
pub const SlotMeta = struct {
/// The number of slots above the root (the genesis block). The first
/// slot has slot 0.
slot: Slot,
/// The total number of consecutive shreds starting from index 0 we have received for this slot.
/// At the same time, it is also an index of the first missing shred for this slot, while the
/// slot is incomplete.
consecutive_received_from_0: u64,
/// The index *plus one* of the highest shred received for this slot. Useful
/// for checking if the slot has received any shreds yet, and to calculate the
/// range where there is one or more holes: `(consumed..received)`.
received: u64,
/// The timestamp of the first time a shred was added for this slot
first_shred_timestamp_milli: u64,
/// The index of the shred that is flagged as the last shred for this slot.
/// None until the shred with LAST_SHRED_IN_SLOT flag is received.
last_index: ?u64,
/// The slot height of the block this one derives from.
/// The parent slot of the head of a detached chain of slots is None.
parent_slot: ?Slot,
/// The list of slots, each of which contains a block that derives
/// from this one.
child_slots: std.ArrayList(Slot),
/// Connected status flags of this slot
connected_flags: ConnectedFlags,
/// Shreds indices which are marked data complete. That is, those that have the
/// data_complete_shred set.
completed_data_indexes: SortedSet(u32),
};在处理 shreds 时,我们不仅更新 shred 的 slot 的元数据,而且还更新其父 slot 和子 slot 元数据。我们称之为链式 slots。这包括更新相关 SlotMeta 实例上的以下字段:
- parent_slot: 来自此 slot 的任何 shreds 将指定哪个 slot 在它之前,因此我们将更新
parents_slot以标识它。 - connected_flags: 如果当前 slot 已完成(意味着收到了所有 shreds),并且它之前的所有 slots 也已完成,则我们将其标记为“已连接”。
- child_slots: 如果终于收到了来自一个 slot 的所有 shreds,我们会更新每个
SlotMeta,它的连接列表现在可以更新。例如,假设我们已经收到了来自 slots 1-3 和 5-7 的每个 shred,而只收到来自 slot 4 的一些 shred。这意味着每个插槽都有一组child_slots,如下所示:
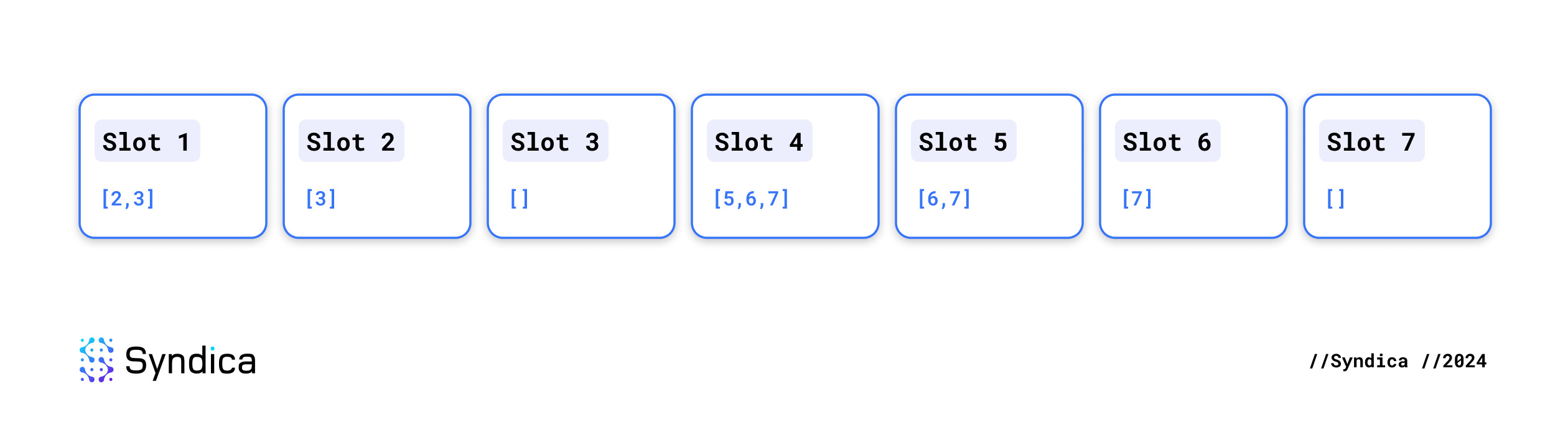 🔍 点击图片放大
🔍 点击图片放大
在收到来自 slot 4 的最后一个 shred 后,它们会像这样更新:
 🔍 点击图片放大
🔍 点击图片放大
这是在 ledger/shred_inserter/slot_chaining.zig 中实现的。
检查 Merkle 根链
账本应该由 erasure sets 的连续序列组成。leader 可能会通过创建两个具有相同索引的不同 erasure sets 来违反此规则。我们要求 leader 将 erasure sets “链接”在一起,以便尽快检测到此类问题。
每个 erasure set 必须指定之前出现的 erasure set 的 Merkle 根,称为其 chained Merkle root。如果 leader 在链中产生任何不连续性,我们将在获得一对矛盾的 shreds 时立即检测到它。无需处理整个 erasure set。这也使验证器可以轻松地相互证明 leader 行为不当。你所需要做的就是向某人展示这两个矛盾的 shreds,并且违规行为已得到证明。
通过这种机制,集群可以快速有效地就行为不当的 leader 达成共识,并删除其无效块。
我们对这轮 shred 插入期间触及的每个 erasure set 进行两次检查:
- 正向链接: 查看是否已收到来自 下一个 erasure set 的任何 shreds。如果是这样,请确保其 chained Merkle root 与当前 erasure set 的 Merkle 根相同。
- 反向链接: 查看是否已收到来自 先前的 erasure set 的任何 shreds。如果是这样,请确保其 Merkle 根与当前 erasure set 的 “chained Merkle root” 相同。
这是在 ledger/shred_inserter/merkle_root_checks.zig 中实现的。
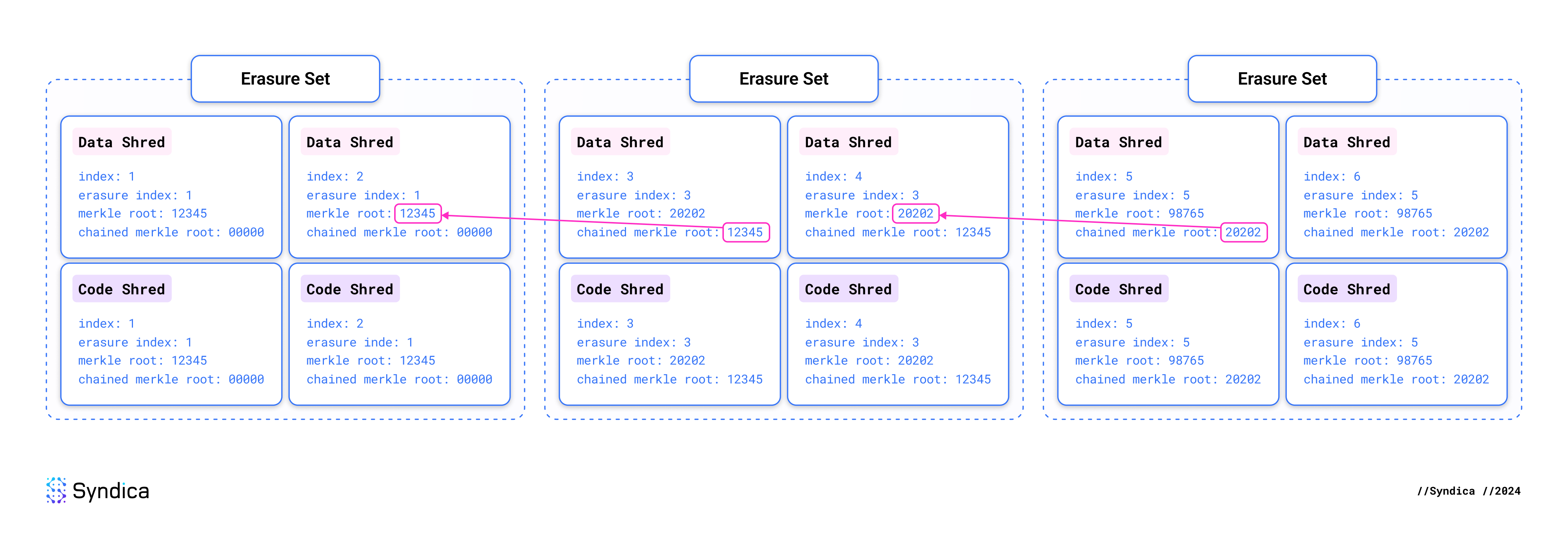 🔍 点击图片放大
🔍 点击图片放大
提交插入
insertShreds 中的最后一步是用单个原子操作将所有挂起状态存储在 Blockstore 中。
为此,会检查 PendingInsertShredsState 结构中的状态是否有任何修改过的数据。每个修改过的项目都使用 put 操作插入到 write batch 中。然后,write batch 将以原子方式提交到数据库。
账本结果写入器
LedgerResultWriter 负责写入交易状态和其他块结果,这两者都 不 在 shreds 中。此数据通常在重放阶段执行在 shreds 中找到的交易时生成。
账本结果模式
在重放交易或达成共识后,我们将获得关于每个交易、块和插槽的新信息。此元数据存储在以下列族中:
交易元数据:
transaction_status: 关于已执行交易的元数据,例如它们是否成功或失败,返回了哪些数据,以及交易的其他影响。address_signatures: 将每个帐户与和此帐户互动的交易相关联。transaction_memos: 描述交易的可选的、用户提供的消息。
块 & 插槽元数据:
bank_hash: 由块更改的所有帐户的组合哈希。blocktime: 生成块的时间。block_height: 在特定插槽之前,整个历史中产生的块的总数。rooted_slots: 指示哪些插槽是根插槽。当对该插槽达成共识时,插槽是 “rooted ”的。这意味着来自该插槽的块会永久包含在链上。optimistic_slots: 跟踪已被共识乐观确认的插槽,以及该验证器将其识别为已确认的哈希和时间。rewards: 块对 leader 的奖励。perf_samples: 账本通过插槽和交易的进行速度。
交易状态
更新交易状态在 writeTransactionStatus 函数中实现。此函数的主要作用是将交易状态直接插入到 transaction_status 列族中。它还会修改 address_signatures 列族,以确定哪些帐户可能已被交易修改。
transaction_status 列族包含 TransactionStatusMeta 数据结构,该结构包含交易本身,以及来自交易的所有输出数据,包括任何状态更改:
pub const TransactionStatusMeta = struct {
/// Whether the transaction succeeded, or exactly what error caused it to fail
status: ?TransactionError,
/// Transaction fee that was paid by the fee payer.
fee: u64,
/// Lamport balances of every account in this transaction before it was executed.
pre_balances: []const u64,
/// Lamport balances of every account in this transaction after it was executed.
post_balances: []const u64,
/// Instructions that were executed as part of this transaction.
inner_instructions: ?[]const InnerInstructions,
/// Messages that were printed by the programs as they executed the instructions.
log_messages: ?[]const []const u8,
/// Token account balances of every token account in this transaction before it was executed.
pre_token_balances: ?[]const TransactionTokenBalance,
/// Token account balances of every token account in this transaction after it was executed.
post_token_balances: ?[]const TransactionTokenBalance,
/// Block rewards issued to the leader for executing this transaction.
rewards: ?[]const Reward,
/// Addresses for any accounts that were used in the transaction.
loaded_addresses: LoadedAddresses,
/// Value that was provided by the last instruction to have a return value.
return_data: ?TransactionReturnData,
/// Number of BPF instructions that were executed to complete this transaction.
compute_units_consumed: ?u64,
};Blockstore 读取器
BlockstoreReader 是负责从账本读取数据的结构。它提供对块、交易、条目和交易状态的访问,这些对于验证器组件(如 RPC 和重放)可用。它从数据库中的大多数列族读取数据。
要从块读取任何数据,Blockstore 读取器必须从其组成 shred 构造块的条目。实现此功能的核心函数称为 getSlotEntriesInBlock,它提取 shreds 并将其转换为条目。
要使用此函数,你需要指定希望包含完整条目的 shred 范围,并且它将通过以下步骤提供这些条目:
- 遍历指定范围内的每个 shred 索引,并从数据库中检索该 shred。
- 在收集完所有这些 shreds 的列表后,执行
deshred,它将来自每个 shred 的数据连接成一个字节数组。 - 使用 bincode 将字节数组反序列化为
Entry结构的列表。Bincode 是一种专为 Rust 设计的序列化格式。我们在 Zig 中实现了一个bincode库以实现兼容性。
这是从 shreds 重建块的本质,但它并没有就此结束。
为了使条目对 Solana 验证器的其他组件有用,BlockstoreReader 需要支持以下所有内容:
- 读取条目(如上所述)。
- 读取整个块。
- 读取交易。
读取条目
某些组件(如 RPC 或账本工具)需要直接从 Blockstore 中读取条目。为了支持这一点,BlockstoreReader 公开了三个公共函数,允许其他组件从数据库中读取条目。这些函数通过调用 getSlotEntriesInBlock 以及一些额外的逻辑来满足其特定需求。
Sig 支持这些函数中的每一个,以确保与 Agave 的 Blockstore 具有功能对等性。Agave 的类似函数用于以下用途:
get_entries_in_data_block用于通知 RPC 订阅者有关新交易的信息。get_slot_entries由账本工具用于列出根。get_slot_entries_with_shred_info由账本工具用于计算插槽的成本并获取最新的乐观插槽。
以下是在 Sig 中实现类似函数的方式:
getEntriesInDataBlock: 这是getSlotEntriesInBlock的公共版本。它本质上是相同的函数,但具有更易于使用的输入参数。getSlotEntries: 这与getSlotEntriesInBlock类似,只是它会自动计算出哪些 erasure sets 已完成,而无需要求你将其作为输入提供。此函数用于从 Blockstore 中读取交易。它的实现方式如下:- 1. 调用
getCompletedRanges以识别我们拥有所有 shreds 的 erasure sets。此函数检查索引以确定哪些完整的 erasure sets 可用于转换为条目。 - 2. 调用
getSlotEntriesInBlock以获取完成范围的所有条目。 - 3. 返回所有提供的条目,并指示我们是否拥有来自该插槽的每个 shred。
- 1. 调用
getSlotEntriesWithShredInfo: 这与getSlotEntries的功能相同,只是它提供更多上下文,例如我们是否已收到该插槽的所有 shreds。
读取整个块
仅仅读取几个条目并不总是足够的。通常,验证器需要检查整个块,其中包含更多元数据和一个方便的已解析交易列表。这是通过 getCompleteBlockWithEntries 实现的,包含以下步骤:
- 调用
getSlotEntriesWithShredInfo以获取所需插槽的所有条目。 - 通过从为该块创建的最后一个条目中提取历史证明哈希来识别块哈希。
- 从每个条目中提取交易并填充单个交易列表。
- 从数据库中提取每个交易的状态。
- 提取每个条目的摘要,并创建这些摘要的列表。
- 从数据库中的每个这些列族中提取数据。
transaction_status: 对于块中的每个交易rewards: 对于插槽blocktime: 对于插槽block_height: 对于插槽- 遍历所有条目并以
EntrySummary的形式提取有关它们的某些元数据,这些元数据可以与交易一起使用以重建原始条目。 - 在步骤 3-7 期间收集的所有数据将作为函数的输出返回。
VersionedConfirmedBlockWithEntries 是 getCompleteBlockWithEntries 返回的数据:
/// Confirmed block with type guarantees that transaction metadata is always
/// present, as well as a list of the entry data needed to cryptographically
/// verify the block.
const VersionedConfirmedBlockWithEntries = struct {
block: VersionedConfirmedBlock,
entries: ArrayList(EntrySummary),
};
/// Confirmed block with type guarantees that transaction metadata
/// is always present.
pub const VersionedConfirmedBlock = struct {
allocator: Allocator,
previous_blockhash: []const u8,
blockhash: []const u8,
parent_slot: Slot,
transactions: []const VersionedTransactionWithStatusMeta,
rewards: []const ledger.meta.Reward,
num_partitions: ?u64,
block_time: ?UnixTimestamp,
block_height: ?u64,
};
// Data needed to reconstruct an Entry, given an ordered list of transactions in
// a block.
const EntrySummary = struct {
num_hashes: u64,
hash: Hash,
num_transactions: u64,
starting_transaction_index: usize,
};getCompleteBlockWithEntries 是支持所有其他 Blockstore 函数(用于公开来自 Blockstore 的块)的后备实现:
getCompleteBlock: 放弃条目摘要,仅返回VersionConfirmedBlock。需要此功能才能在请求已确认的块时支持getBlockRPC 方法。getRootedBlockWithEntries: 这添加了一个检查以确保请求的块已扎根。如果不是,则返回错误。
注意: Agave 中的类似函数 get_rooted_block_with_entries 用于将已确认的块更新到 Google Cloud Bigtable。上载到 Bigtable 使节点能够存储比本地存储更多的块,从而允许它们为较旧的数据提供 RPC 请求。
getRootedBlock: 这从getRootedBlockWithEntries返回VersionConfirmedBlock。与getCompleteBlock类似,需要此功能才能在请求已完成的块时支持getBlockRPC 方法。
读取交易
Blockstore reader 的一个重要用例是读取交易。getTransaction RPC 方法需要 Blockstore 提供已确认或已完成的交易,这将分别取决于函数 getCompleteTransaction 和 getRootedTransaction。这两个函数执行相同的操作,只是 getCompleteTransaction 还在未扎根的插槽中查找交易。
它们由一个名为 getTransactionWithStatus 的私有函数实现,该函数运行以下步骤:
- 从
transaction_status列族获取交易状态。这也告诉我们哪个插槽有交易。 - 既然我们知道哪个插槽包含交易,请调用
findTransactionInSlot以从该插槽获取交易,该插槽处理步骤 3 和 4。 - 调用
getSlotEntries(如上所述),该函数返回该插槽的所有条目。 - 遍历每个条目中的每个交易,直到我们找到具有请求签名的交易。
- 返回交易及其状态。
用于读取交易数据的另一个函数称为 getConfirmedSignaturesForAddress。它允许你获取地址已参与的所有交易的列表,并且它由 getSignaturesForAddress RPC 方法使用。它从 address_signatures 列族读取交易数据,该列族首先按地址排序,然后按插槽排序。此排序使你可以轻松检索特定地址的所有交易。
特定地址可能有数百万个交易,这使得提取所有交易的成本非常高。为了解决此问题,getConfirmedSignaturesForAddress 允许你指定要接收信息的有限交易范围。可以通过可选地指定你感兴趣的最旧和最新的交易签名来配置此选项。这是通过使用 getTransactionStatus 来识别交易来自哪个插槽来实现的,从而使我们可以将搜索范围缩小到仅查看我们关心的插槽范围内的签名。此函数中的大多数代码复杂度都存在于支持这种复杂的筛选机制。
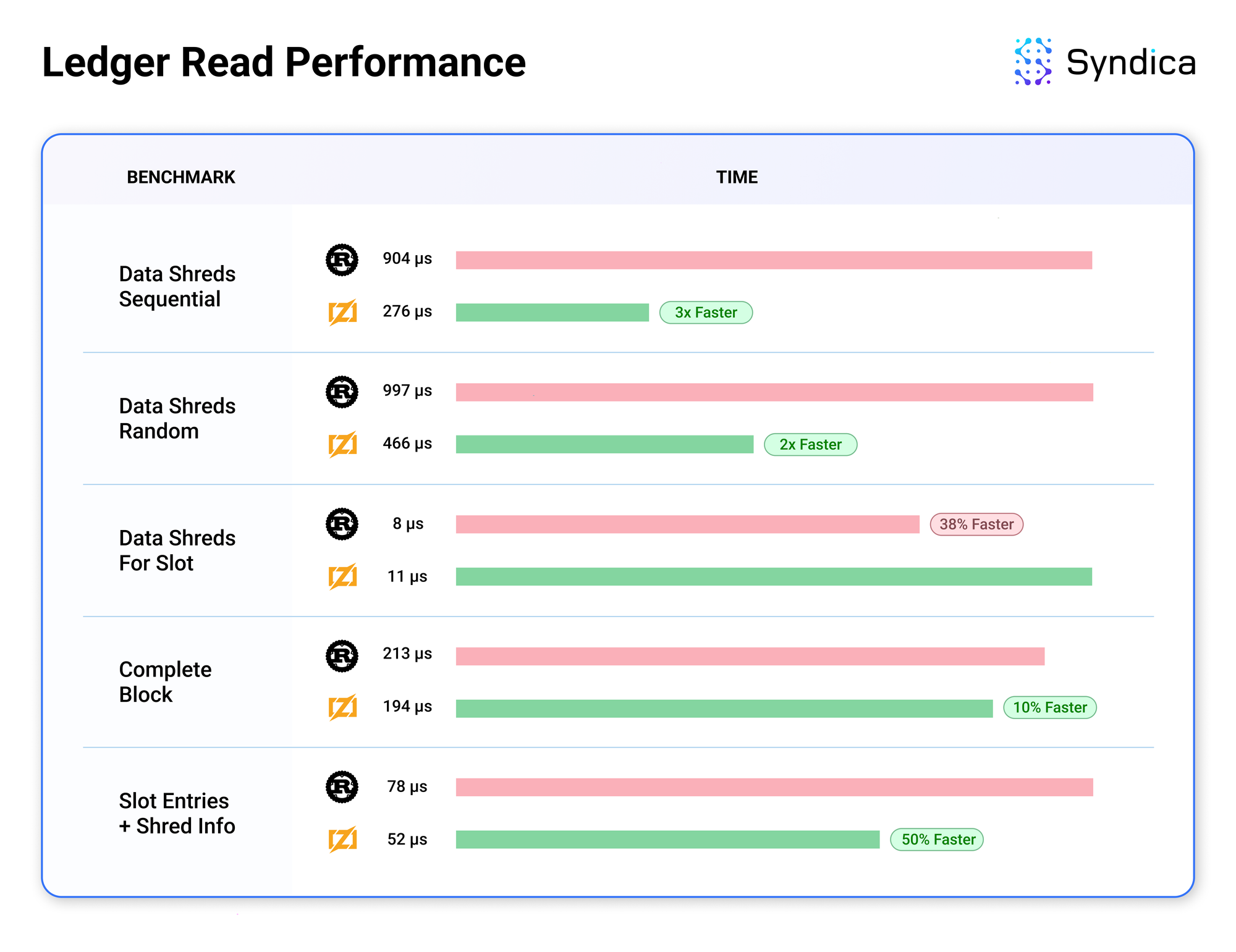
基准
我们记录了来自 Sig 初始账本实现的基准数据,以将其性能与 Agave 进行比较。
 🔍 点击图片放大
🔍 点击图片放大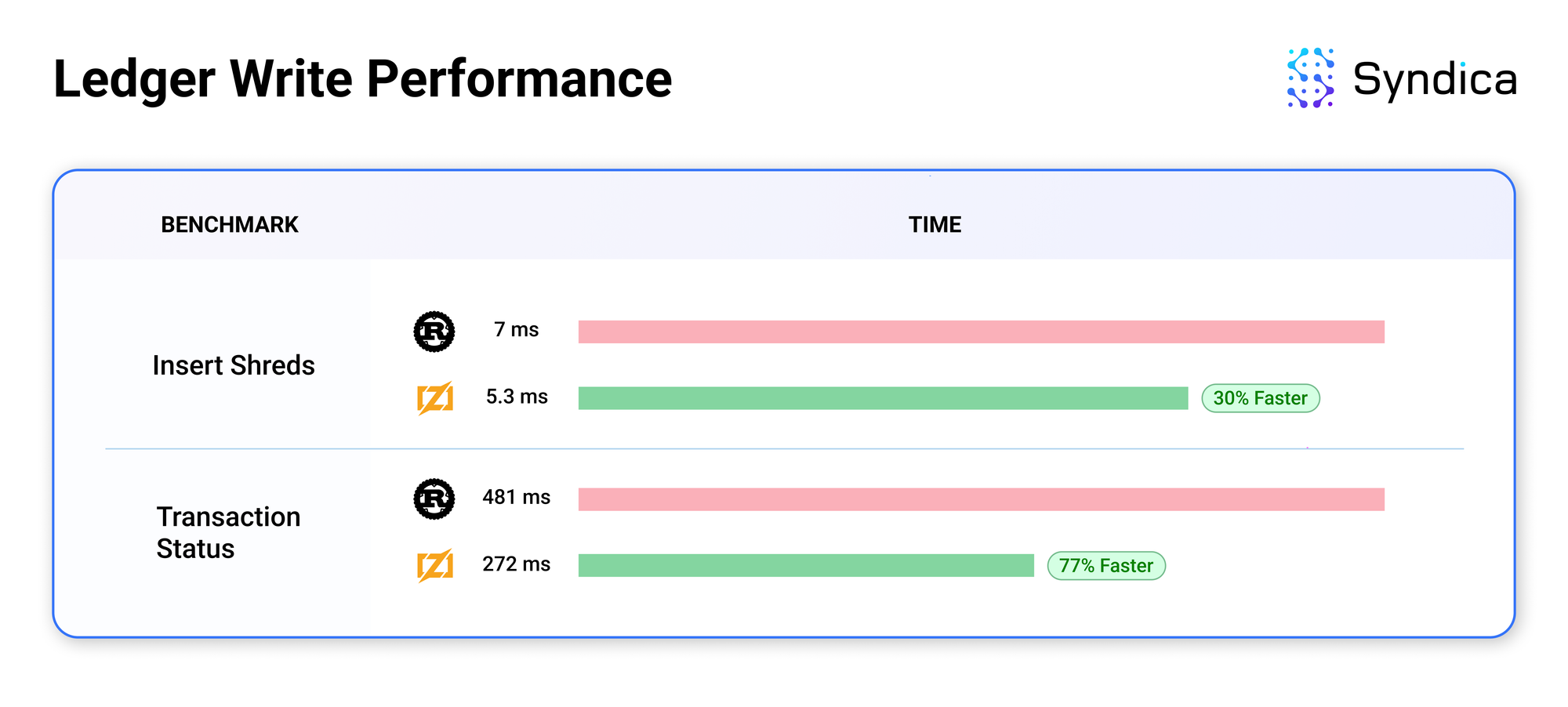 🔍 点击图片放大
🔍 点击图片放大
结果令人鼓舞,因为 Sig 的账本通常超过 Agave 的性能。性能提升可能是由于 Zig 带来的底层改进,例如减少内存分配的数量。我们才刚刚开始进行优化以进一步提高性能。Sig 的账本的模块化架构使代码具有适应性且易于改进,这意味着这些优化将易于实现。
我们鼓励开发人员为 Sig 的开发做出贡献。我们对 GitHub 上的 pull requests 持开放态度。我们也在扩大我们的团队。查看我们的职业页面以了解开放的职位。如果你有任何问题,请通过 电子邮件、Discord 或 Twitter 与我们联系。
- 原文链接: blog.syndica.io/sig-engi...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





