关于Solidity 事件,我希望早一点了解到这些
- Tiny熊
- 发布于 2023-07-06 19:27
- 阅读 7214
在这篇文章中,详细说明的事件的日志是如何生成,索引是如何影响日志的生成,字符串等变长数据是如何处理的。同时介绍了在前端如何获取事件。
以太坊是一个世界计算机,网络中的每个节点都在运行它的代码实现,而以太坊区块链是这些节点对世界计算机最新状态的集体约定。
以太坊计算机的一个关键组成部分是,确定的状态更新,对于最新状态的共识来说是必要的。以太坊的目标是去中心化,网络中的每个节点必须能够处理新区块中的交易,并拥有与网络中所有其他节点相同的结果最新状态。能够实现这一点的原因之一,是由于以太坊计算机(即以太坊虚拟机)是沙盒化的。这种沙盒化意味着EVM的能力是有限的,因此,给定一组输入,只能有一个输出。这就是每个执行最新交易的节点总是能到达区块链的同样的最新状态。
虽然确定性的状态更新是实现共识的理想选择,但在梳理Web2和以太坊时,有一些权衡因素会带来独特的挑战。其中一个限制是以太坊智能合约如何与存在于所有以太坊沙盒虚拟机之外的世界沟通。造成这种限制的部分原因是,从EVM到外部世界的调用是不确定的。想象一下,你有一个智能合约,向一个网络API发出API请求,以获得一对资产的最新价格。当节点A处理一个触发这个API调用的交易时,它收到一个42的响应,并相应地更新它的最新状态。然后当节点B处理同样的交易时,价格发生了变化,所以它收到的响应是40,并相应地更新了它的最新状态。然后节点C发出请求,并收到一个404的HTTP响应,因为API离线了一秒钟,那么节点C如何更新它的状态呢?无论如何,你可以看到一个更大的问题,即从EVM到它的沙盒之外的世界的调用可能不总是产生相同的响应。如果允许这样做,那么当网络中的每个节点都可能对最新状态有不同的看法时,以太坊世界计算机就无法对最新状态达成共识。
为了帮助解决Web2和以太坊之间的通信问题,EVM允许生成日志。在Solidity中,我们通过触发事件来利用这些日志。
以太坊的日志
在底层,在Solidity中触发事件会指示EVM执行以下操作码(之一):LOG0、LOG1、LOG2、LOG3或LOG4(你可以查看它们的细节这里)。当一个事件被触发时,LOG操作码产生一个日志条目,包括触发事件的合约地址,一个主题数组和一些数据。主题来自事件的indexed索引参数,每个LOG操作码后有一个数字,表示它可以处理的主题数量可以0个 到4个)。日志的 data属性来自非索引的事件参数,能记录多少数据的限制是存储数据的Gas成本(目前每个字节的数据有8个Gas + 下面图片中显示的一些其他值)、和区块的Gas限制(即使你愿意支付大量的Gas来存储你的数据,你的交易也很有可能超过当前区块允许使用的Gas总量--特别是当你考虑到你的交易可能不是唯一使用该区块 Gas 配额的交易)。
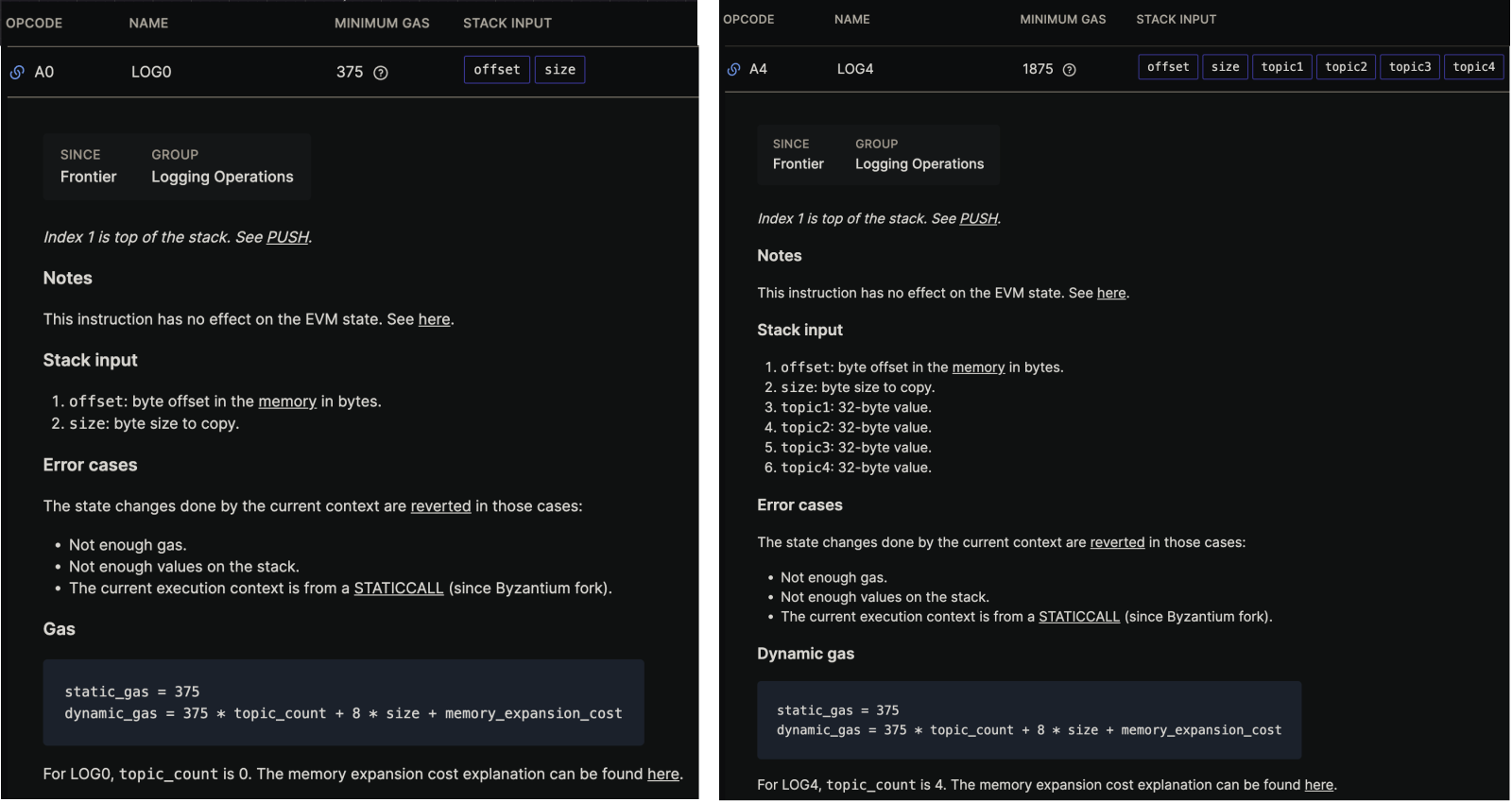
LOG EVM 操作码文档
当LOG指令被执行时,生成的日志条目被存储在EVM内的交易上下文中,这是一个EVM处理交易时的临时空间。这个交易上下文保存着当前正在处理的交易的信息,包括对状态的任何改变,以及产生的日志条目。一旦交易被 EVM 处理并准备好被纳入区块链,就会创建一个交易收据。该收据是交易执行的摘要,包括状态、使用的Gas和产生的日志。
下面是一个交易收据的例子,为了简洁起见,一些数据被省略了,但你可以在这里查看整个收据:
{
status: "0x1",
gasUsed: "0x879e",
logs: [
{
address: "0x6b175474e89094c44da98b954eedeac495271d0f",
blockHash:
"0x4230f9e241e1f0f2d466bbe7450350bfe1abceab2dac74c3c1c52443b2e5f307",
blockNumber: "0x10b4c1d",
data: "0x0000000000000000000000000000000000000000000000068155a43676e00000",
logIndex: "0xd1",
removed: false,
topics: [
"0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef",
"0x000000000000000000000000b0b734cfc8c50f2742449b3946b2f0ed03e96d77",
"0x000000000000000000000000ff07e558075bac7b225a3fb8dd5f296804464cc1"
],
transactionHash:
"0x81b886145c37afe0e42353e81f8f2896dd69fb86531a6d2ee9a13ced4d9321fb",
transactionIndex: "0x52"
}
]
}从这个收据中,我们可以看出这个交易发出了一个事件(因为logs.length == 1),有3个主题(因为logs[0].topic.length == 3),因此使用了操作码LOG3。
以太坊日志主题
如上一节所述,主题来自于事件的indexed参数,每个LOG操作码跟着一个相应的数字,表示它可以包含的主题数量(可以0个 到4个)。主题提供了一种有效的方法,可以方便的从一个区块中的所有交易中过滤出感兴趣的事件。
但主题是如何产生的呢?
每个主题有一个最大长度为32字节的数据,每个主题都被编码为这个最大长度,即使数据不占用32字节。正如你在上面的交易收据中看到的,我们有一个主题是
0x000000000000000000000000b0b734cfc8c50f2742449b3946b2f0ed03e96d77其中实际数据b0b734cfc8c50f2742449b3946b2f0ed03e96d77只有20字节长,但被填充了0以达到32字节的长度。
Solidity事件确实支持其值可能超过这个32字节的最大长度的数据类型,例如动态大小的数组和字符串,在这些情况下,值的keccak256散列被用作主题,而不是值本身。
命名事件
上面的交易收据是与Dai Stablecoin合约的transfer功能交互的交易结果。我们知道它,是因为交易指定的to地址是以太坊主网Etherscan上的一个经过验证的合约:

经过验证的Dai稳定币地址
如果我们看一下这个合约的验证的合约代码,我们可以看到,在第95行,声明了一个名称为Transfer的事件:
event Transfer(address indexed src, address indexed dst, uint wad);我们还可以看到,这个 Transfer事件有两个 indexed参数,src和 dst,以及一个非索引参数,wad。回到我们的交易收据上的topics数组:
topics: [
"0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef",
"0x000000000000000000000000b0b734cfc8c50f2742449b3946b2f0ed03e96d77",
"0x000000000000000000000000ff07e558075bac7b225a3fb8dd5f296804464cc1"
],你可以看到有3个主题,而我们的事件只定义了两个indexed参数,那么第三个主题是什么?在Solidity中,当事件被命名为 Transfer这样的名字时,Solidity 会使用事件签名,使用keccak256散列算法对其进行散列,并将其作为第一个元素附加到 topics数组中。所以在我们的topics数组中,0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef是我们Transfer方法的事件签名的散列。为了进一步证明这个想法,让我们跟随 Solidity 的过程来生成我们的事件签名的哈希值。
首先,什么是事件签名?
事件签名
在 Solidity 中,事件签名是一个事件的唯一标识符,由事件的名称和它的参数类型生成。对于我们的 Transfer事件,Dai Stablecoin合约中经过验证的合约代码的第95行:
event Transfer(address indexed src, address indexed dst, uint wad);现在,Solidity 并不只是直接采取上述内容,对其进行哈希处理,然后得到哈希的事件签名。相反,Solidity首先将事件签名中的关键字和参数名称剥离。对于我们的 Transfer 事件,这些剥离的值将是:
eventindexedsrcdstwad- 任何空格
;
这样,我们剩下的就是:
请记住,虽然经过验证的合约代码使用 uint作为value参数的数据类型,但uint是uint256的别名,Solidity在生成散列事件签名时将使用完整的类型名称,因此我们在下面使用uint256。
Transfer(address,address,uint256)现在 Solidity 对剥离的事件签名进行散列,以生成我们的预期主题值。使用这个在线keccak256哈希函数,你可以看到散列剥离的事件签名确实给了预期的值,我们在日志的topics数组中看到了第一个元素。
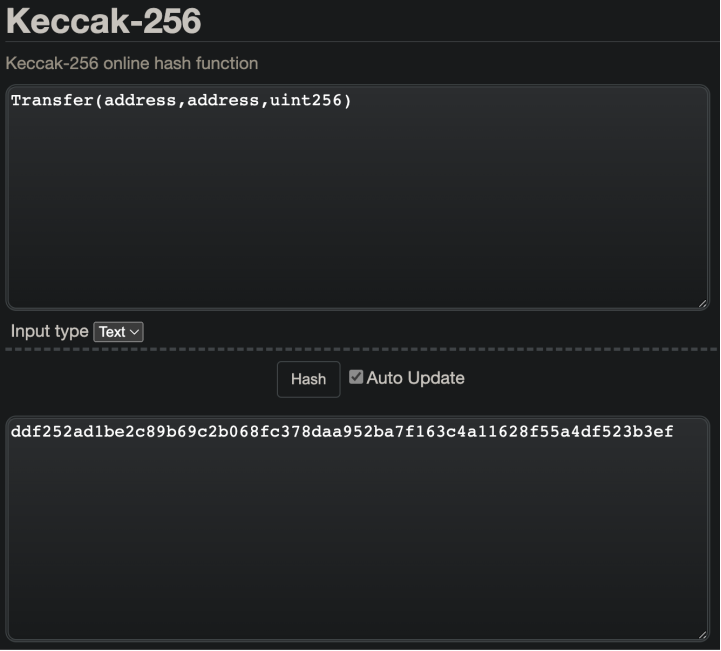
转移事件签名的Keccak256哈希值
剩余的事件主题
那么,我们已经弄清楚了日志的topics数组中的第一个元素,接下来的两个元素呢?我们知道topics数组包含了indexed事件参数,所以其他的主题是src和dst,但是这些值是怎么来的呢?当我们查看Etherscan上的交易收据,并点击+点击显示更多按钮,我们可以看到该交易的输入数据:

DAI稳定币转账输入数据
点击解码输入数据按钮,我们可以得到这个输入数据的一个更容易理解的版本:

解码后的Dai稳定币转账输入数据
这是向以太坊提交交易时用户提供的数据。正如你所看到的,这个交易正在调用Dai Stablecoin合约上的transfer函数,其数据为:0xfF07E558075bAc7b225A3FB8dD5f296804464cc1作为dst参数,120000000000000000作为wad参数。
查看Etherscan上经过验证的合约代码,我们看到transfer功能存在于122 - 124行:
transfer会调用另一个函数transferFrom(来自第125-137行),所以我也列出了这个函数,以便我们有额外的背景信息:
function transfer(address dst, uint wad) external returns (bool) {
return transferFrom(msg.sender, dst, wad);
}
function transferFrom(address src, address dst, uint wad)
public returns (bool)
{
require(balanceOf[src] >= wad, "Dai/insufficient-balance");
if (src != msg.sender && allowance[src][msg.sender] != uint(-1)) {
require(allowance[src][msg.sender] >= wad, "Dai/insufficient-allowance");
allowance[src][msg.sender] = sub(allowance[src][msg.sender], wad);
}
balanceOf[src] = sub(balanceOf[src], wad);
balanceOf[dst] = add(balanceOf[dst], wad);
emit Transfer(src, dst, wad); // <--- Here is where the `Transfer` event is being emitted
return true;
}在第135行,我们看到:
emit Transfer(src, dst, wad);这是交易收据中看到的事件的确切代码。所以当交易的发送方调用transfer函数时,它调用transferFrom函数,将msg.sender作为src参数(这是交易发送方的地址),并提供dst和wad参数。因此,当Transfer事件最终在第135行被触发(即被记录)时,这些是被记录到区块链上的值,并在我们的事件日志中显示在交易收据中。
为了清楚起见,下面的代码示例包括传递给函数的参数和Transfer事件:
// This is dst wad
function transfer(0xfF07E558075bAc7b225A3FB8dD5f296804464cc1, 120000000000000000000) external returns (bool) {
// This is msg.sender dst wad
return transferFrom(0xB0B734CFC8c50F2742449B3946B2f0eD03E96D77, 0xfF07E558075bAc7b225A3FB8dD5f296804464cc1, 120000000000000000000);
}
// This is src dst wad
function transferFrom(0xB0B734CFC8c50F2742449B3946B2f0eD03E96D77, 0xfF07E558075bAc7b225A3FB8dD5f296804464cc1, 120000000000000000000)
public returns (bool)
{
// Irrelevant implementation code...
// This is src dst wad
emit Transfer(0xB0B734CFC8c50F2742449B3946B2f0eD03E96D77, 0xfF07E558075bAc7b225A3FB8dD5f296804464cc1, 120000000000000000000);
return true;
}因此,当看我们的topics数组时,我们的交易收据中的日志:
topics: [
"0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef", // 事件签名的 keccak256 值
"0x000000000000000000000000b0b734cfc8c50f2742449b3946b2f0ed03e96d77", // src 参数
"0x000000000000000000000000ff07e558075bac7b225a3fb8dd5f296804464cc1" // dst 参数
],但是为什么src和dst的值看起来与我们在触发事件时传递的值不同呢?好吧,如果你记得以太坊日志主题部分的开头的描述:
每个主题都有一个最大长度为32字节的数据,每个主题都被编码为这个最大长度,即使数据不占用32字节。
地址只有20字节长,所以这些值被填充了0,以便它们变成32字节长(这是每个事件主题必须使用的长度)。
那缺少的wad参数呢?
也许你注意到,当我们在第135行发出 Transfer事件时,我们传递了 src、dst和 wad事件参数的值,但只有 src和 dst显示在日志的 topics数组中 - wad参数发生了什么?看一下Transfer的事件签名:
event Transfer(address indexed src, address indexed dst, uint wad);我们可以看到 wad参数没有被 indexed。在 Solidity 中,所有未被索引的事件参数都是 ABI 编码的,并存储在事件的data属性中。看一下交易收据,我们可以看到wad的值被填充到32字节,并保存在logs[0].data下:
传递给 Transfer事件的数据是12000000000000000,但是Solidity会把整数转换成十六进制以节省空间。12000000000000000转换为十六进制是:68155a43676e00000
{
status: "0x1",
gasUsed: "0x879e",
logs: [
{
address: "0x6b175474e89094c44da98b954eedeac495271d0f",
blockHash:
"0x4230f9e241e1f0f2d466bbe7450350bfe1abceab2dac74c3c1c52443b2e5f307",
blockNumber: "0x10b4c1d",
// This is wad converted to hexidecimal and padded to be 32 bytes
data: "0x0000000000000000000000000000000000000000000000068155a43676e00000",
logIndex: "0xd1",
removed: false,
topics: [
"0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef",
"0x000000000000000000000000b0b734cfc8c50f2742449b3946b2f0ed03e96d77",
"0x000000000000000000000000ff07e558075bac7b225a3fb8dd5f296804464cc1"
],
transactionHash:
"0x81b886145c37afe0e42353e81f8f2896dd69fb86531a6d2ee9a13ced4d9321fb",
transactionIndex: "0x52"
}
]
}匿名事件
因此,如果一个命名的事件的第一个主题是哈希的事件签名,怎么能有使用LOG0的事件呢,而这个事件没有记录的主题?让我们进入匿名事件!
当在Solidity中声明一个事件时,你可以选择使用anonymous关键字,像这样:
event RegularEvent();
event AnonymousEvent() anonymous;
event AnonymousEventWithParameter(address indexed sender) anonymous;当一个 anonymous 事件被触发时,散列的事件签名不会作为一个主题被包含在事件的 topics 数组中。
下面是一个例子,如果 RegularEvent 被触发,交易收据的事件日志:
{
logs: [
{
data: "0x0",
topics: [
// RegularEvent() 的 keccak256 hash
"0xef6f955afa69850e8e58a857ef80f5ab7e81117d116a10f94b8c57160c4631d9"
]
}
]
}如果 AnonymousEvent 被触发:
{
logs: [
{
data: "0x0",
// There are no topics for this event log because we have no `indexed` parameters,
// 匿名事件,没有事件签名被包含
topics: []
}
]
}如果触发了AnonymousEventWithParameter:
{
logs: [
{
data: "0x0",
topics: [
// This is an address padded to 32 bytes i.e. the sender event parameter
"0x000000000000000000000000b0b734cfc8c50f2742449b3946b2f0ed03e96d77"
]
}
]
}匿名事件使用案例
额外的自定义索引参数
由于EVM目前只支持操作码 LOG0-4,一个事件日志最多只能有四个 主题。对于命名的事件,第一个主题被保留给散列的事件签名,只留下3 个空间给自定义indexed参数。如果一个事件被声明为 匿名,那么哈希签名就不会被记录,从而为一个额外的 indexed参数留出空间。这在需要索引超过3个参数的特定情况下是很有用的。
event AnonymousEventWithFourParameters(uint256 indexed one, uint256 indexed two, uint256 indexed three, uint256 indexed four) anonymous;{
logs: [
{
data: "0x0",
topics: [
"0x0000000000000000000000000000000000000000000000000000000000000001",
"0x0000000000000000000000000000000000000000000000000000000000000002",
"0x0000000000000000000000000000000000000000000000000000000000000003",
"0x0000000000000000000000000000000000000000000000000000000000000004"
]
}
]
}节省 Gas
因为事件签名不存储在日志中,你可以减少事件的Gas成本。例如,如果你的合约事件不多,可以很容易地通过事件主题的数量来区分,像这样:
event HasOneTopic(uint256 indexed one) anonymous;
event HasTwoTopics(uint256 indexed one, uint256 indexed two) anonymous;
event HasThreeTopics(uint256 indexed one, uint256 indexed two, uint256 indexed three) anonymous;
{
logs: [
// This is an example event log for HasOneTopic
{
data: "0x0",
topics: [
"0x0000000000000000000000000000000000000000000000000000000000000001"
]
},
// This is an example event log for HasTwoTopics
{
data: "0x0",
topics: [
"0x0000000000000000000000000000000000000000000000000000000000000001",
"0x0000000000000000000000000000000000000000000000000000000000000002"
]
},
// This is an example event log for HasThreeTopics
{
data: "0x0",
topics: [
"0x0000000000000000000000000000000000000000000000000000000000000001",
"0x0000000000000000000000000000000000000000000000000000000000000002",
"0x0000000000000000000000000000000000000000000000000000000000000003"
]
}
]
}可以节省一些,尽管是非常少的Gas,因为我们可以依靠logs[].topics.length来辨别出是哪一个匿名事件被触发出来。
模糊化
匿名事件可以使查验区块链的人更难确定发出的是哪种事件,因为事件签名不包括在日志中。这可以被看作是混淆合约行为的一种方式,但是应该注意的是,通常认为智能合约的操作是透明的,这是最佳做法。
例如,以这两个事件为例:
event SuperSecret(uint256 indexed passcode) anonyomous;
event Decoy(uint256 indexed decoy) anonymous;如果一个合约发出几个 Decoy事件和一个 SuperSecret事件,那么在查验更新秘密的交易日志时,就很难分辨出实际的秘密是什么。在下面的日志中,你能分辨出哪个是SuperSecret事件,而不是Decoy事件?
{
logs: [
{
data: "0x0",
topics: [
"0x0000000000000000000000448960cc9a23414c19031475fc258eba8000000000"
]
},
{
data: "0x0",
topics: [
"0x000000000000000000000000def171fe48cf0115b1d80b88dc8eab59176fee57"
]
},
{
data: "0x0",
topics: [
"0x00000000000000000000000089b78cfa322f6c5de0abceecab66aee45393cc5a"
]
},
{
data: "0x0",
topics: [
"0x000000000000000000000000a950524441892a31ebddf91d3ceefa04bf454466"
]
},
{
data: "0x0",
topics: [
"0x0000000000000000000000009759a6ac90977b93b58547b4a71c78317f391a28"
]
}
]
}并不是说这是一个具体的例子,但它说明了匿名事件的一个潜在使用场景。
注意事项
筛选交易的困难
匿名事件的最大缺陷可能是它使过滤使用它们的交易变得困难。正如上面混淆的例子中所讨论的,你如何能够过滤那些只更新秘密并发出SuperSecret事件的交易呢?如果没有对合约的一些额外的了解,你是无法做到的,因为仅仅看一下交易收据是不明显的。然而,你可以绕过这个限制,就像在Gas节省部分所讨论的那样,使用不同数量的事件主题来辨别不同的事件。
事件冒充
在混淆部分也描述了,如果没有事件签名的哈希值作为事件日志的唯一标识符,具有相同事件参数的 anonymous 事件在被记录时结构是相同的。因此,它可能看起来像一个SuperSecret事件,但实际上,所有的事件都可能是Decoy事件,而你却无从得知。如果一个特定的 anonymous 事件被用来执行一些链外操作,而一个具有相同索引事件参数的假事件被触发出来,这可能是危险的。
indexed 字符串发生了什么?
当我们在讨论事件的 topics时,我想快速指出一个问题,如果你试图在你的事件中使用 string indexed。在某些时候,你会想发出一个带有一些string值的事件,你可能会想使用indexed,因为它是一个重要的字符串,你的dApp可以访问。这种情况看起来类似于:
event WhatHappenedToMyString(string indexed importantString);
function emitMyString() public {
emit WhatHappenedToMyString("Super important string");
}现在,当我们调用这个emitMyString函数时,你可能希望看到类似的东西:
{
logs: [
{
data: "0x0",
topics: [
"0x9a765dc5bb2a8596b4e4c72e864f3d2be32ff913a128d6b1343df14329065f89",
"0x00000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000000016537570657220696d706f7274616e7420737472696e6700000000000000000000"
]
}
]
}好吧......也许你没料到,因为那不是我们的字符串,Super important string。
关于ABI编码的旁白
那么,如果我们把 "Super important string"作为我们的 "字符串"值触发出去,为什么我们会看到这个奇怪的数字,而不是 "Super important string"?
"0x00000000000000000000000000000000000000000000000000000000000000200000000000000000000000000000000000000000000000000000000000000016537570657220696d706f7274616e7420737472696e6700000000000000000000"这是因为一个叫做ABI编码的东西,我可以写一篇关于这个话题的文章,但现在我将保持相对简短的解释。
那么什么是ABI编码?首先,让我们听听ChatGPT的解释:
以太坊应用二进制接口(ABI)是一个标准,用于数据在智能合约的高级代码和以太坊虚拟机(EVM)的低级机器语言之间进行编码和解码。它规定了将高层数据类型(如字符串和数组)转换为EVM可以处理的标准化格式的方法。这包括指定如何将函数调用,包括其名称和参数,编码为EVM的字节数。ABI在与智能合约的交互中起着至关重要的作用,允许用户和外部程序理解合约的结构、函数和变量,并与之进行相应的交互。
所以基本上,ABI编码是我们如何将人类可读的数据转换成EVM可以理解的标准化机器可读数据。为了进一步说明这一点,让我们分解一下如何从 "Super important string" 到ABI编码表示的过程。
首先,我们需要了解 "Super important string" 已经使用了一种叫做UTF-8的数据编码形式。我链接了一篇关于 UTF8 是什么以及我们为什么使用它的文章,但让ChatGPT来总结一下:
UTF-8标准将每个字符表示为一到四个字节的唯一序列。ASCII字符(包括所有字母数字字符和一些符号)是UTF-8的一个子集,ASCII字符为一个字节。
因此,我们将人类可读字符串转换为机器可读数据的第一步是将我们的UTF-8字符串转换成它的字节表示。因为我们使用的是UTF-8的ASCII子集,我们知道每个字符都是用1个字节表示的,但是我们如何将UTF-8转换成字节呢?
那么,以太坊选择利用的一个直接的解决方案是使用十六进制来表示每个字节。你可以查看这里,一个将UTF-8字符转换为十六进制字节的表格。使用这个表格,我们可以看到,将我们的字符串转换为十六进制的字节将看起来像:
'S' = '53'
'u' = '75'
'p' = '70'
'e' = '65'
'r' = '72'
' ' (space) = '20'
'i' = '69'
'm' = '6D'
'p' = '70'
'o' = '6F'
'r' = '72'
't' = '74'
'a' = '61'
'n' = '6E'
't' = '74'
' ' (space) = '20'
's' = '73'
't' = '74'
'r' = '72'
'i' = '69'
'n' = '6E'
'g' = '67'将上述内容拼成一行,我们可以得到:537570657220696d706f7274616e7420737472696e67.敏锐的人将注意到,这种十六进制字节的组合实际上存在于我们正在建立的ABI编码数据中:

编码字符串事件数据
那么,如果我们找到了ABI编码的字符串,其余的数据是干什么用的呢?EVM是为处理32字节的数据块而建立的,也称为字。如果你回顾一下以太坊日志主题部分的开头,每个事件主题也是32字节的字。因此,让我们采取完整的ABI编码的字符串,并把它分成这些32字节的字:
0x0000000000000000000000000000000000000000000000000000000000000020 // 第一个字,
0000000000000000000000000000000000000000000000000000000000000016 // second,
537570657220696d706f7274616e7420737472696e6700000000000000000000 // and third除去数据开头的0x(这只是一个前缀,表示下面的数据将被解释为十六进制),我们有3个EVM字:
1.0000000000000000000000000000000000000000000000000000000000000020: 从这第一个字中除去所有的 0,我们得到 20。将其从十六进制转换为整数,我们得到32。这第一个字是告诉EVM,从这个数据块的从 32字节数据开始。所以从前缀0x后的0开始,我们数32字节(64个十六进制字符,因为1字节由2十六进制字符表示),我们得到...
2.0000000000000000000000000000000000000000000000000000000000000016:从这第二个字中除去所有的 0,我们得到 16。转换为整数,我们得到22。这第二个字是告诉EVM存在一些22字节长的数据。所以EVM加载下一个字...
3.537570657220696d706f7274616e7420737472696e6700000000000000000000:你可能已经认识到,这是我们的字符串,"Super important string",被编码为它的十六进制格式的UTF-8字符。我们的数据后面剩下的0是确保我们的EVM字达到预期的32字节长度(因为我们的字符串只有22字节长)
所以总结一下,我们的巨大的数据块是告诉EVM的:我们有一些数据可能不适合在一个32字节的EVM字中。这个数据从第 32字节开始,这个数据是22字节长,然后最后它给EVM的数据进行解析,使用我们给它的信息,所以它解析了22字节,得到我们的十六进制UTF-8字符串。
为什么要用这么多数据来表示22字节的字符串?
你可能想知道为什么我们需要前两个EVM字来理解我们的十六进制编码的字符串。这是因为 字符串可以有一个不确定的长度。其他的值,如uint和int可以放入32字节的EVM字中,因为这些值的最大长度是32字节(例如,uint256是256位长,256位是32字节(8位=1字节,所以256/8=32))。
虽然我们的字符串,"Super important string" ,适合于一个32字节的EVM字,我们可以很容易地想象一个很多字符串不是这样。以supercalifragilisticexpialidocious为例。这个字符串是34UTF-8字符长(即34字节长),它长到足以超过32字节的EVM字(2字节太长)。所以,Supercalifragilisticexpialidocious ABI 编码是:
0x0000000000000000000000000000000000000000000000000000000000000020 // First word,
0000000000000000000000000000000000000000000000000000000000000022 // second,
737570657263616c6966726167696c697374696365787069616c69646f63696f // third,
7573000000000000000000000000000000000000000000000000000000000000 // fourth如果没有前2个EVM字告诉我们string数据从哪里开始,以及它有多长,我们就只能是:
737570657263616c6966726167696c697374696365787069616c69646f63696f
7573000000000000000000000000000000000000000000000000000000000000如果这就是EVM的全部工作,它将假定每个32字节的字是独立的数据,这意味着我们的原始字将被视为两个独立的字:
1.supercalifragilisticexpialidocio (737570657263616c6966726167696c697374696365787069616c69646f63696f)
2.us (7573000000000000000000000000000000000000000000000000000000000000)
所以为了避免将我们的 字符串分割成基于每32个字节的多个字,我们告诉EVM我们的 字符串数据从哪里开始,以及它是多少个字节。在supercalifragilisticexpialidocious的例子中,第二个EVM字说它是34字节长(0x22=34),所以EVM解析下一个34字节作为我们的字符串数据(这是第三个字的整个32字节,和第四个EVM字的2字节)。
对 "indexed" 字符串的实际处理情况
我们知道事件的 topics必须是32字节长,但是 string的长度可以超过32字节,那么当你发出一个带有 indexed字符串参数的事件时会发生什么呢?简单地说,我们使用字符串值的keccak256哈希值,并将其作为topic。这是可能的,因为keccak256哈希值总是32字节长,所以这个策略总是有效的,不管我们的字符串数据有多长。
回到我们的indexed字符串事件的例子:
event WhatHappenedToMyString(string indexed importantString);
function emitMyString() public {
emit WhatHappenedToMyString("Super important string");
}当emitMyString被调用时,我们的事件日志实际上会看起来像:
{
logs: [
{
data: "0x0",
topics: [
"0x9a765dc5bb2a8596b4e4c72e864f3d2be32ff913a128d6b1343df14329065f89",
"0x8415478cebd2e698dbda720fc2a07faf3d46dc907f1cc27ccd5cbc61609eea21"
]
}
]
}其中8415478cebd2e698dbda720fc2a07faf3d46dc907f1cc27ccd5cbc61609eea21是Super important string的哈希值:

Keccak-256字符串的哈希值
使用 indexed 字符串的注意事项
虽然仍然可以使用原始indexed字符串数据的哈希值来过滤交易,但如果你需要在某个地方使用原始字符串数据,例如在你的dApp中显示它,那么只有哈希值就没有什么用了。
不过有一个方便的解决方法,通过不对字符串事件参数使用indexed,触发的字符串数据将被ABI编码,并在事件日志的data属性(logs[].data)下可用:
event WhatHappenedToMyString(string importantString); //...



