更快的Sumcheck:第一部分
本文围绕 sumcheck 协议在“小域证明值、大域随机性”场景下的加速展开,重点分析了减少大域乘法的几种优化方案。
注意
这篇文章需要对 sumcheck protocol 有一定了解。如果你不熟悉它,建议先阅读我们的交互式教程:使用 SageMath 学习 Sumcheck 和 MLEs
引言
在这一系列文章中,我们将介绍 Speeding Up Sum-Check Proving 论文中描述的优化。为了便于理解,我们还分享了这些算法在 SageMath 中的实现,可在 GitHub 上获取。
这篇论文的主要动机,是加速一种特定场景下的 sumcheck 证明:待证明的值位于一个小域中,而随机性则来自一个相对较大的域。例如,在证明 zkVM 时,我们通常需要证明寄存器值是 32 位整数,以及标志位是布尔值。另一方面,出于安全原因,我们通常会在 sumcheck 中从一个大域中抽取随机性,例如,基于哈希的 SNARK 使用约 128 位域,或基于椭圆曲线的 SNARK 使用约 256 位域。
这意味着在整个 sumcheck protocol 中,prover 需要承担大量大域上的运算成本,而这些运算通常比小域上的运算慢得多。
更具体地说,我们可以将 sumcheck protocol 中的算术运算(这里只考虑乘法)分为三类:
- ss:小 × 小
- sl:小 × 大
- ll:大 × 大
由于 ll 乘法最昂贵,论文的目标就是尽量减少这类乘法的数量。
预备知识
在深入讨论这些优化之前,我们先来看一些预备知识。
多线性多项式
设 $p:F^l \to F$ 为一个 multilinear polynomial。那么,我们可以使用 $eq~$ 多项式,将其表示为某个布尔超立方体 ${0,1}^l$ 上加权求值的和:
$p(x_1,x_2,\dots,x_l)=\sum_{b\in{0,1}^l}eq~((x_1,x_2,\dots,x_l),b)\cdot p(b)$,
其中 $x_1,x_2,\dots,x_l\in F$ 是变量,$p(b)$ 是在布尔超立方体上的取值,而 $eq~((x_1,x_2,\dots,x_l),b)$ 是权重。
我们可以通过遍历 $x_i$ 的布尔取值并将结果相加,来移除任意变量 $x_i$。例如,如果我们要移除 $x_l$,就会得到如下等式:
$p(x_1,x_2,\dots,x_{l-1})=\sum_{x'\in{0,1}^1}\sum_{b\in{0,1}^{l-1}}eq~((x_1,x_2,\dots,x_{l-1}),b)\cdot p(b,x')$。
类似地,我们也可以给 $x_i$ 赋予 $F$ 中的任意值。例如,我们可以将 $(x_1,x_2,\dots,x_{l-1})=(r_1,r_2,\dots,r_{l-1})$ 代入上式,得到:
$p(r_1,r_2,\dots,r_{l-1})=\sum_{x'\in{0,1}^1}\sum_{b\in{0,1}^{l-1}}eq~((r_1,r_2,\dots,r_{l-1}),b)\cdot p(b,x')$。
这两个技巧就是我们在 sumcheck protocol 中所需要的一切。
Sumcheck Protocol
在整个 sumcheck protocol 中,在每一轮 $i$,我们都会为 $x_i$ 计算一个一元多项式,并在大域中的随机值 $r_i$ 处对其求值。
例如,在第 $i=1$ 轮,我们构造如下的一元多项式 $s_1$:
$s_1(X)=\sum_{x'\in{0,1}^{l-1}}\sum_{b\in{0,1}^1}eq~(X,b)\cdot p(b,x')$。
然后,我们将 $s_1$ 在大域中的随机值 $r_1$ 处求值并发送给 verifier,从而得到如下等式:
$s_1(r_1)=\sum_{x'\in{0,1}^{l-1}}\sum_{b\in{0,1}^1}eq~(r_1,b)\cdot p(b,x')$。
对于一般的第 $i$ 轮,一元多项式如下:
$s_i(X)=\sum_{x'\in{0,1}^{l-i}}\sum_{b\in{0,1}^{i-1}}eq~((r_1,\dots,r_{i-1}),b)\cdot p(b,X,x')$。
对多线性多项式乘积进行 Sumcheck
在这篇文章中,我们将研究一个特殊情况:对 $d$ 个 multilinear polynomials $p_1,p_2,\dots,p_d$ 的乘积运行 sumcheck。因此,我们将方程 $s_i(X)$ 重写为:
$s_i(X)=\sum_{x'\in{0,1}^{l-i}}\prod_{k=1}^d\left(\sum_{b\in{0,1}^{i-1}}eq~((r_1,\dots,r_{i-1}),b)\cdot p_k(b,X,x')\right)$
算法 1:使用 evaluation table
现在我们准备深入讨论了!
在每一轮中计算 $s_i(X)$ 的一种简单方法,是保留每个 $p_k(X)$ 在布尔超立方体 ${0,1}^{l-i}$ 上所有取值的表,并在轮次推进时持续更新。
这需要一个大小为 $d\cdot 2^l$ 的初始表,并且在之后的每一轮中,所需大小都会减半。
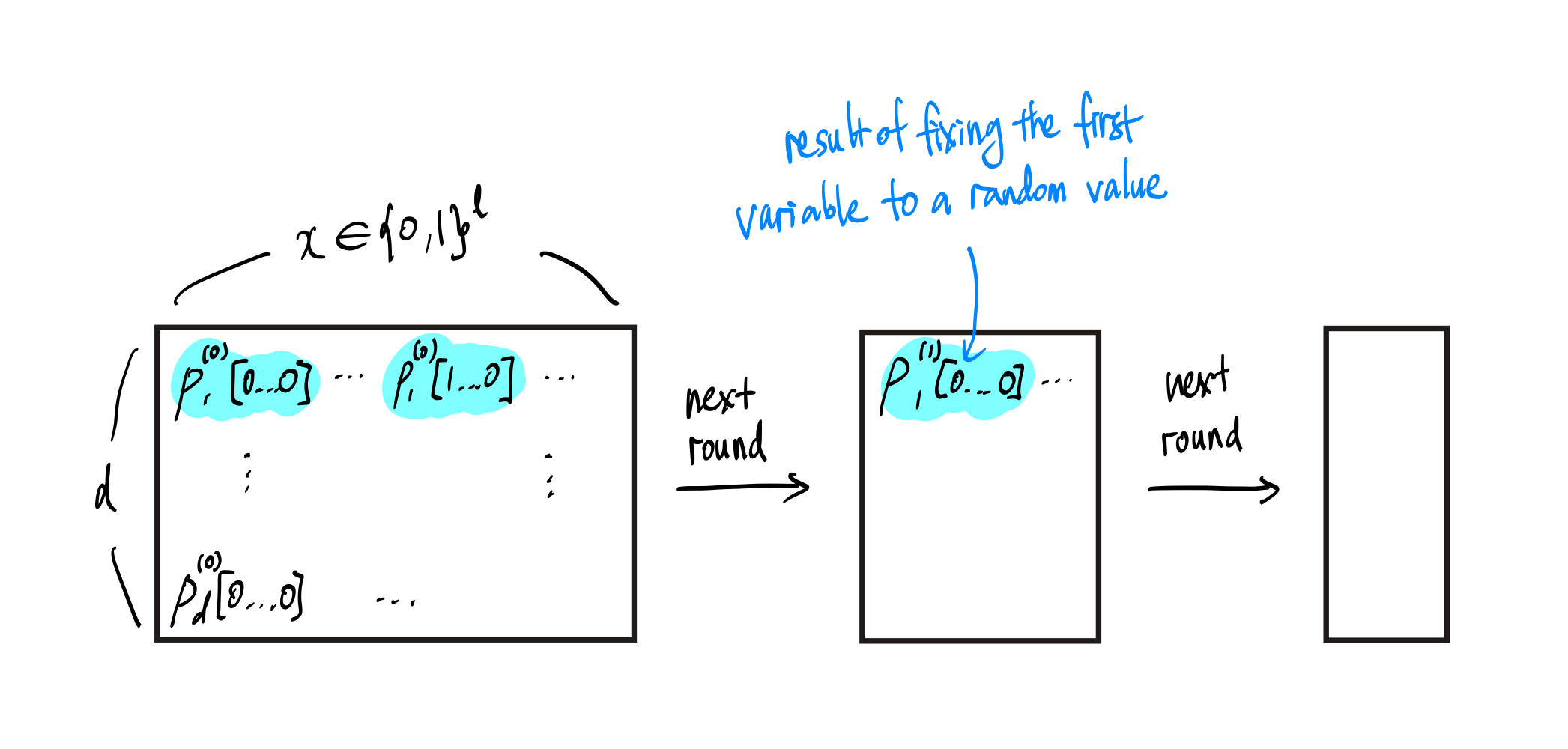
图 1.1:从第 $i=1$ 轮开始的 evaluation table。
一个简单的观察是,这种方法在空间和时间上都效率低下,因为初始表很大,而且从第二轮开始我们就需要执行 $ll$ 乘法。
我们能做得更好吗?
注意
查看该算法的 SageMath 代码。
算法 2:直接为每一轮计算 $p_k$
解决空间问题的一个简单办法,是直接计算所有 $b\in{0,1}^{i-1}$、$x'\in{0,1}^{l-i}$ 以及 $k\in[d]$ 的 $p_k(b,X,x')$,直到 evaluation table 的大小变得足够小。
例如,我们可以一直直接计算这些多项式直到第 $l/2$ 轮,然后切换到算法 1;此时我们将从一个大小为 $d\cdot 2^{l/2}$ 的表开始,而不是 $d\cdot 2^l$。
不过,我们仍然没有解决从第二轮开始的 $ll$ 乘法问题。
注意
查看该算法的 SageMath 代码。
算法 3:预计算与 $r$ 无关的项
分离 good 与 bad
注意,一旦一个小值与一个大值相乘,之后对结果进行的任何进一步算术运算都会变成 $ll$ 乘法。因此,为了尽量减少 bad($ll$ 乘法),我们会尽可能推迟大值和小值的相乘,从而把 good($ss$ 乘法)与 bad 分离开来。
回忆 prover 需要计算的方程如下:
$s_i(X)=\sum_{x'\in{0,1}^{l-i}}\prod_{k=1}^d\left(\sum_{b\in{0,1}^{i-1}}eq~((r_1,\dots,r_{i-1}),b)\cdot p_k(b,X,x')\right)$。
可以看到,这要求在遍历所有 $x'$、$k$ 和 $b$ 之前,先将 $eq~$ 项(一个大值)与 $p_k$ 项(一个小值)相乘,从而得到一个大值。
然而,如果我们对每一项分别遍历 $x'$、$k$ 和 $b$,然后再将结果相乘,就能最小化 $ll$ 乘法的数量!此外,$p_k$ 与 $r$ 无关,因此我们可以预先计算这些值。
让我们逐步来看如何做到这一点。
首先,我们交换对 $b$ 的求和与对 $k$ 的乘积的顺序:
$\sum_{x'\in{0,1}^{l-i}}\sum_{b_1,\dots,b_d\in{0,1}^{i-1}}\prod_{k=1}^d(eq~((r_1,\dots,r_{i-1}),b_k)\cdot p_k(b_k,X,x'))$。
如果对 $b_1,\dots,b_d$ 的新求和看起来不太熟悉,请注意,内层乘积现在会遍历所有 ${b_1,\dots,b_d}$,因此我们需要遍历这些变量的所有可能取值。
接下来,我们展开 $eq~$ 函数的定义。注意,$eq~$ 有两种表示:
$eq~((r_1,\dots,r_{i-1}),b_k)=\prod_{j=1}^{i-1}(r_j\cdot b_k[j]+(1-r_j)\cdot(1-b_k[j]))=\prod_{j=1}^{i-1}(r_j b_k[j]\cdot(1-r_j)^{1-b_k[j]})$,
我们将使用第二种表示。
因此,我们得到如下新表达式:
$\sum_{x'}\sum_{b_1,\dots,b_d}\prod_{k=1}^d\left(\prod_{j=1}^{i-1}(r_j b_k[j]\cdot(1-r_j)^{1-b_k[j]})\cdot p_k(b_k,X,x')\right)$。
让我们再进一步,把对 $k$ 的乘积与对 $j$ 的乘积交换。
$\sum_{x'}\sum_{b_1,\dots,b_d}\left(\prod_{j=1}^{i-1}r_j^{\sum_{k=1}^d b_k[j]}\cdot(1-r_j)^{d-\sum_{k=1}^d b_k[j]}\right)\cdot\left(\prod_{k=1}^d p_k(b_k,X,x')\right)$。
最后,让我们把对 $x'$ 的求和移到内部,放在对 $k$ 的乘积之前。由于 $r$ 项不依赖于 $x'$,这个求和本身不需要做任何改变。
$\sum_{b_1,\dots,b_d}\left(\left(\prod_{j=1}^{i-1}r_j^{\sum_{k=1}^d b_k[j]}\cdot(1-r_j)^{d-\sum_{k=1}^d b_k[j]}\right){\text{$r$-dependent term}}\cdot\left(\sum{x'}\prod_{k=1}^d p_k(b_k,X,x')\right)_{\text{$r$-independent term}}\right)$。
如你所见,我们最终得到了两个项的乘积:一个依赖于大值 $r$,另一个则不依赖于它。注意,乘法次数等于 $2^{d\cdot(i-1)}$,因为我们对每个多项式都在遍历 $i-1$ 个比特,总共是 $d$ 个多项式。下图展示了 $d=3$ 且 $i=5$ 时的可视化表示。
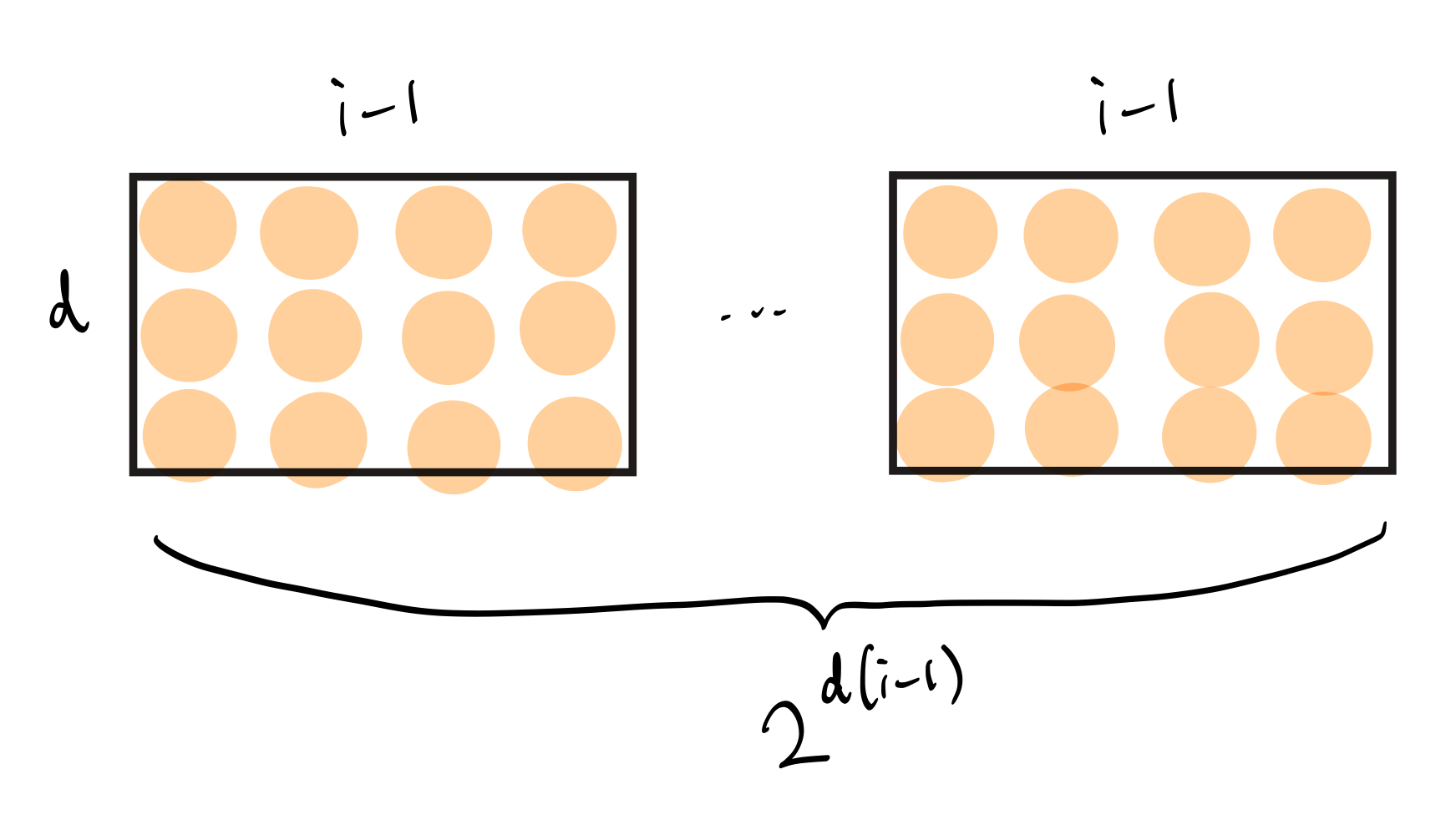
图 3.1:上方每个橙色圆圈都代表一个布尔值,图示说明了遍历所有 $d\times(i-1)$ 个比特。
但是我们能让乘法次数更少吗?结果是可以的!
将 d 个比特分组为一个 [0,d] 标量值
这个优化的关键观察是,$r$ 相关项依赖的不是单个 $d\cdot(i-1)$ 个比特,而是在 1 到 $i-1$ 之间某个特定索引处的 $d$ 个比特之和。你可以看到,下面这些项中的指数,就是在对索引 $j$ 处的 $d$ 个比特求和:
$\prod_{j=1}^{i-1}r_j^{\sum_{k=1}^d b_k[j]}\cdot(1-r_j)^{d-\sum_{k=1}^d b_k[j]}$。
因此,我们可以遍历 $d$ 个比特所有可能的 和,而不是所有可能的 $d$ 个比特。这样立刻就将可能值从 $2^d$ 个变为 $d+1$ 个(对于 $d$ 个比特,最小和为 $0$,最大和为 $d$)。因此,总迭代次数从 $2^{d\cdot(i-1)}$ 减少到 $(d+1)^{i-1}$。
接下来,我们还需要改变对与 $r$ 无关项的遍历方式。我们仍然遍历同样的 $2^{d\cdot(i-1)}$ 个可能值,但顺序不同。
更具体地说,对于每个 $[0,d]^{i-1}$ 中的和,我们会遍历所有加总后等于给定和的 $d$ 个比特的可能取值。下图给出了 $d=3$ 且 $i=5$ 的可视化示例。
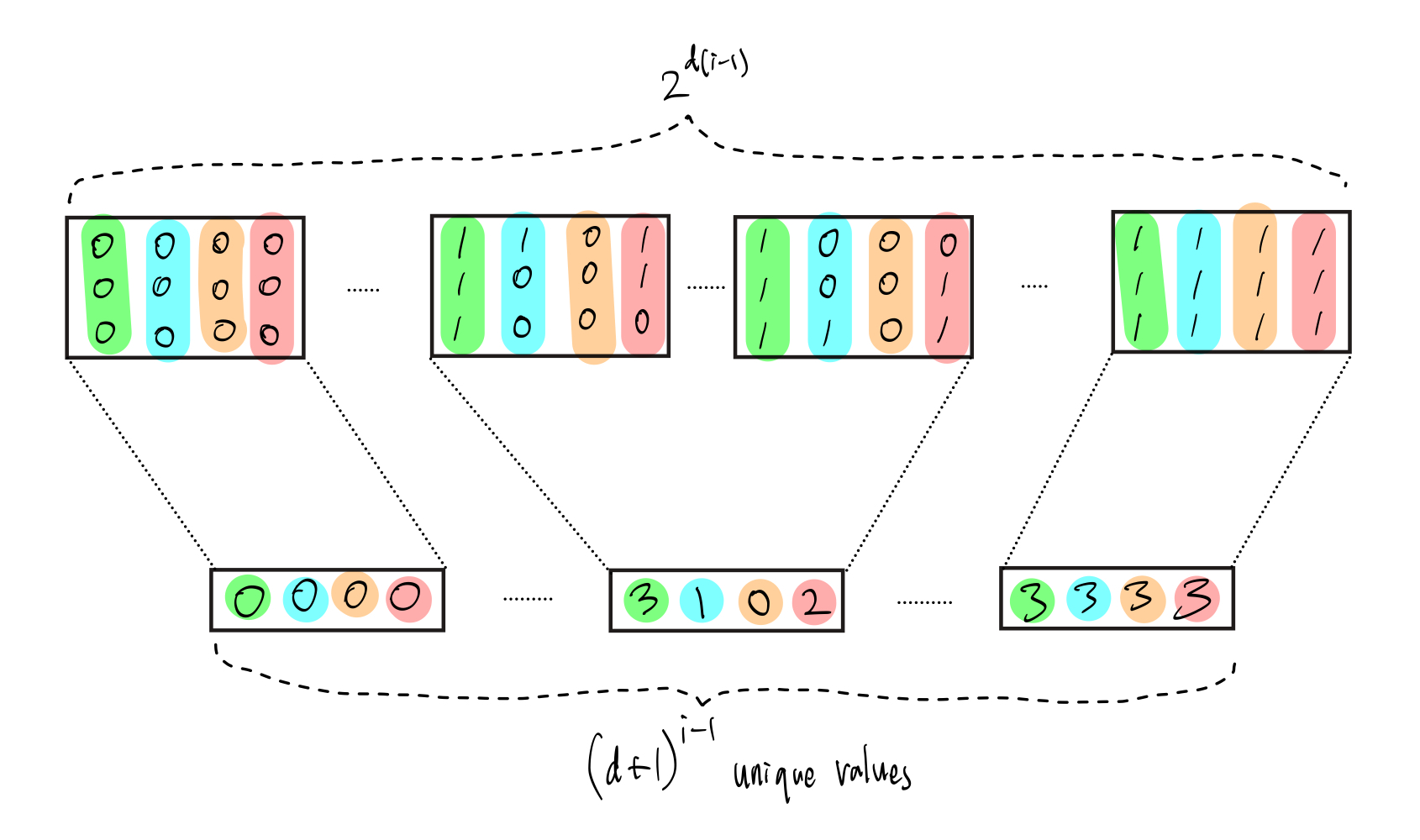
图 3.2:下方矩形表示 $(d+1)^{i-1}$ 个值,而上方矩形表示 $2^{d\cdot(i-1)}$ 个值,虚线展示了每个下方矩形如何对应一个或多个上方矩形。
因此,我们可以定义一个新变量 $v:=(\sum_{k=1}^d b_k[j])_{j\in[i-1]}$,它可以被视为 图 3.2 中的一个下方矩形,并将方程 $s_i(X)$ 重写如下:
$\sum_{v\in[0,d]^{i-1}}\left(\left(\prod_{j=1}^{i-1}r_j^{v[j]}\cdot(1-r_j)^{d-v[j]}\right){\text{$r$-dependent term}}\cdot\left(\sum{x'}\sum_{b_1,\dots,b_d\in{0,1}^{i-1},,v=\sum_{k=1}^d b_k}\prod_{k=1}^d p_k(b_k,X,x')\right)_{\text{$r$-independent term}}\right)$。
$r$ 无关项看起来很复杂,但它实际上只是:对于给定的 $v$,也就是 图 3.2 中的一个下方矩形,遍历所有加总为 $v$ 的 $b_1,\dots,b_d$ 的可能取值,也就是与该下方矩形相连的所有上方矩形。
这意味着我们只是重新组织了计算 $r$ 无关项的方式,但我们已经成功将 $r$ 相关项与无关项之间的乘法数量从 $2^{d\cdot(i-1)}$ 减少到了 $(d+1)^{i-1}$。
预计算 $r$ 无关项,也就是 accumulator
由于 $r$ 无关项只依赖于 $v$ 和 $X$,我们可以定义一个新函数 $A_i(v,X)$ 如下:
$A_i(v,X)=\sum_{x'}\sum_{b_1,\dots,b_d\in{0,1}^{i-1},,v=\sum_{k=1}^d b_k}\prod_{k=1}^d p_k(b_k,X,x')$。
我们将其称为 accumulator,因为它会 accumulate 所有与 $r$ 无关的值。这个 accumulator 的好处在于,由于它不依赖于 verifier 提供的随机性 $r$,我们可以在 sumcheck protocol 开始之前就将其预先计算出来!
递增式计算 $r$ 相关项
在把所有内容整合起来之前,让我们先看看如何简化 $r$ 相关项:
$\prod_{j=1}^{i-1}r_j^{v[j]}\cdot(1-r_j)^{d-v[j]}$
注意,由于每个 $j\in[1,i-1]$ 的 $v[j]$ 有 $d+1$ 种可能值,它可以被看作是 $i-1$ 个大小为 $d+1$ 的数组的 tensor product。例如,给定 $d=2$ 且 $i=3$,该项如下:
$[r_1^0\cdot(1-r_1)^2,r_1^1\cdot(1-r_1)^1,r_1^2\cdot(1-r_1)^0]\otimes[r_2^0\cdot(1-r_2)^2,r_2^1\cdot(1-r_2)^1,r_2^2\cdot(1-r_2)^0]$
这确实会得到 $(d+1)^{i-1}=(2+1)^{3-1}=9$ 个值。
另一个观察是,这个 tensor product 可以递增地计算,也就是说,将上一轮的数组与一个大小为 $d+1$ 的新数组做 tensor product。
因此,我们可以将 $r$ 相关项重写为:
$R_{i+1}:=R_i\otimes(r_i^k\cdot(1-r_i)^{d-k})_{k=0}^d$,
其中初始值设为 1:$R_1=1$。
将所有内容整合起来
现在我们准备把所有内容整合起来了!
我们现在可以将方程 $s_i(X)$ 重写为:
$\sum_{v\in[0,d]^{i-1}}R_i[\text{index}(v)]\cdot A_i(v,X)$,
其中 $\text{index}(v)$ 是 $v$ 在大小为 $(d+1)^{i-1}$ 的数组中的索引。
在实践中,我们不会在整个 sumcheck protocol 中都运行这个算法,而只会在前几轮使用它,然后切换到算法 1。我们建议查看论文的第 4.1 节以了解更多细节。
信息
查看该算法的 SageMath 代码。
算法 4:最终算法
但我们还能做得更好!
算法 4 在保持 $sl$ 和 $ll$ 乘法数量不变的同时,通过减少 $ss$ 乘法的数量,进一步改进了算法 3。
主要动机在于,在算法 3 中,尽管 $r$ 相关项和无关项之间只有 $(d+1)^{i-1}$ 次乘法,但我们仍然需要遍历所有 $b_1,\dots,b_d\in{0,1}^{i-1}$,这相当于 $2^{d\cdot(i-1)}$ 个值。
那么,有没有办法把迭代次数减少到 $(d+1)^{i-1}$ 呢?
简单来说,我们可以把多项式 $\prod_{k=1}^d p_k((r_1,\dots,r_{i-1}),X,x')$ 看作一个关于 $Y_1,\dots,Y_{i-1}$ 的函数,并将其重写为如下形式:
$F(Y_1,\dots,Y_{i-1})=\prod_{k=1}^d p_k(Y_1,\dots,Y_{i-1},X,x')$。
由于每个 $Y_1,\dots,Y_{i-1}$ 的次数都是 $d$,我们可以对每个变量应用 Lagrange interpolation。下面是对该表达式的逐步展开:
$\prod_{k=1}^d p_k(Y_1,\dots,Y_{i-1},X,x')=\sum_{v_1\in[0,d]}L_{v_1}(Y_1)\cdot\prod_{k=1}^d p_k(v_1,Y_2,\dots,Y_{i-1},X,x')=\sum_{v_1\in[0,d]}L_{v_1}(Y_1)\cdot\sum_{v_2\in[0,d]}L_{v_2}(Y_2)\cdot\prod_{k=1}^d p_k(v_1,v_2,Y_3,\dots,Y_{i-1},X,x')=\sum_{v_1\in[0,d]}L_{v_1}(Y_1)\cdot\sum_{v_2\in[0,d]}L_{v_2}(Y_2)\cdots\sum_{v_{i-1}\in[0,d]}L_{v_{i-1}}(Y_{i-1})\cdot\prod_{k=1}^d p_k(v_1,v_2,v_3,\dots,v_{i-1},X,x')=\sum_{v\in[0,d]^{i-1}}\prod_{j=1}^{i-1}L_{v_1}(Y_1)\cdot\prod_{k=1}^d p_k(v,X,x')$。
其中 $b_k[j]$ 是第 $k$ 个多项式的第 $j$ 个比特。
这意味着我们可以遍历 $[0,d]^{i-1}$ 中 $Y_1,\dots,Y_{i-1}$ 的所有可能取值,并在每个向量处对多项式求值。
因此,我们可以将方程 $s_i(X)$ 重写如下:
$s_i(X)=\sum_{x'\in{0,1}^{l-i}}\sum_{v\in[0,d]^{i-1}}\prod_{j=1}^{i-1}L_{v_j}(r_j)\cdot\prod_{k=1}^d p_k(v,X,x')=\sum_{v\in[0,d]^{i-1}}\prod_{j=1}^{i-1}L_{v_j}(r_j){\text{$r$-dependent term}}\cdot\sum{x'\in{0,1}^{l-i}}\prod_{k=1}^d p_k(v,X,x')_{\text{$r$-independent term}}$,
这里,我们再次构造出了 $r$ 相关项与无关项的内积。此外,由于 $L_{v_j}(r_j)$ 项与 $x'$ 无关,我们可以在 sumcheck protocol 开始之前预先计算它们。
信息
查看该算法的 SageMath 代码。
结论
在这篇文章中,我们梳理了如何在待证明的值位于小域、而随机性来自相对较大域的情况下优化 sumcheck protocol。
在下一篇文章中,我们将讨论如何优化大素数域中的 $eq~$ 函数和 $sl$ 乘法。
zkSecurity 提供密码系统的审计、研究和开发服务,包括零知识证明、MPCs、FHE 和共识协议。
- 原文链接: blog.zksecurity.xyz/post...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
 GitHub 登录
GitHub 登录
 Web3 钱包登录
Web3 钱包登录
