Tornado Cash 的工作原理(开发者逐行解析)
- RareSkills
- 发布于 2023-06-29 21:33
- 阅读 4177
本文详细介绍了Tornado Cash的工作原理,包括零知识证明、Merkle Tree的使用以及如何实现匿名加密货币转账。文章还讨论了Tornado Cash的智能合约架构、合法性问题以及潜在的安全风险。

Tornado Cash 介绍
Tornado cash 是一个加密货币智能合约混合器,使用户能够将加密货币存入一个地址并从另一个钱包中取出,而不在这两个地址之间创建可追踪的链接。
Tornado cash 可能是最具代表性的零知识智能合约应用程序,因此我们将以足够低的水平解释它的工作原理,以便程序员可以重现该应用程序。
假设读者知道 Merkle 树如何工作,并且对反转 cryptographic hash 是不可行的。读者还应当被假定至少具有 Solidity 的中级水平(因为我们将会阅读源代码片段)。
Tornado Cash 是一个相对先进的智能合约,因此如果你仍然对该语言不熟悉,请先查看我们的 Solidity 教程。
Tornado Cash 的快速警告
法律问题
Tornado Cash 目前受到美国政府的制裁,进行互动可能会“玷污”你的钱包,并导致以后与中心化交易所交互时标记来自该钱包的交易。
2024 更新:截至 2024 年 11 月 28 日,制裁已由美国上诉法院解除。
Tornado Cash 黑客事件
5 月 27 日, Tornado Cash 治理智能合约(不是我们在这里回顾的智能合约)被黑客攻击,攻击者通过通过了一个恶意提案,从而获得了治理的绝大多数 ERC20 投票代币 ERC20 投票代币用于治理。此后,他们已 收回控制权,留下一小部分给自己。
零知识如何运行(对于厌恶数学的程序员)
你可以在不知道零知识证明算法的情况下理解 Tornado Cash 如何工作,但你必须知道零知识证明的工作原理。与它们的名字和许多流行示例相反,零知识证明证明的是计算的有效性,而不是某个事实的知识。它们并不进行计算。它们取一个商定的计算、一个证明该计算已执行的证明和该计算的结果,然后确定证明者是否真的进行了计算并得出了输出。零知识部分来自于一种可选特性,即计算证明可以以一种不提供输入信息的方式表示。
例如,你可以展示你知道一个数的质因数,而不透露它们,使用 RSA 算法。RSA并不声称“我知道两个秘密数字”;相反,它证明你将两个隐藏的数字相乘并生成了公钥。RSA 加密实际上只是零知识证明的一个特例。在 RSA 中,你证明你知道两个相乘以生成你公钥的秘密素数。在零知识中,你将这种“神秘乘法”推广到任意的算术和布尔运算。一旦我们有了对基本运算的零知识操作,我们可以构建关于更奇特的事物的零知识证明,比如证明我们知道哈希函数的原像、Merkle 根,甚至一个完全功能的虚拟机。
另一个要点:零知识证明验证并不进行计算,它只验证某人是否进行了计算并提交了声称的输出。
还有一个有用的推论:要生成一个计算的零知识证明但不验证,你必须实际进行计算。
这有什么道理?你怎么能证明你知道哈希的原像,而不实际对原像进行哈希呢?因此,证明者确实进行计算并创建一些称为证明的辅助数据,以确认他们确实正确地进行了计算。
当你验证 RSA 签名时,你没有将他人的私钥因素相乘来生成他们的公钥,这对目的来说是徒劳的。你只需验证签名和消息是否匹配,使用一个单独的算法。因此,一个计算由以下内容组成:
verifier_algorithm(proof, computation, public_output) == true在 RSA 的上下文中,你可以认为公钥是计算的结果,而签名和消息是零知识证明。
计算和输出都是公开的。我们同意我们在使用某个哈希函数并得到了某个输出。证明“隐藏”了使用的输入,仅证明哈希函数已执行并生成了输出。
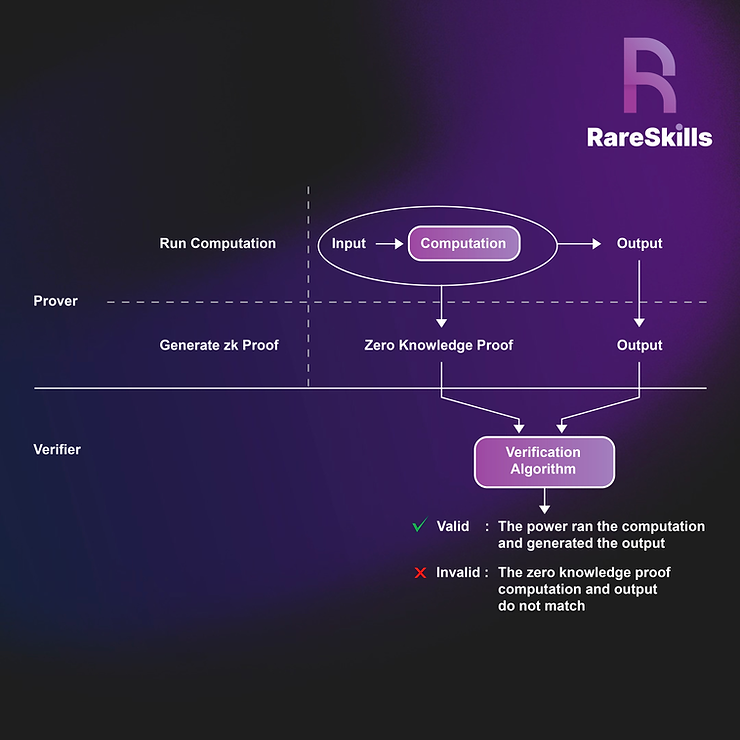
仅凭证明,验证者无法计算 public_output。验证步骤并不进行计算,它仅验证基于证明的声称计算产生的公共输出。
我们在本文中不会教授零知识算法,但只要你能接受我们可以证明计算发生而不自己进行计算,那我们就好继续进行。
匿名加密货币转账如何工作:混合
从根本上讲,Tornado Cash 的匿名化策略是混合,这类似于其他匿名加密货币如 Monero。多个用户将他们的加密货币提交到一个地址,将他们的存款“混合”在一起。然后他们以一种方式提取这些存款,以确保存款者和撤回者无法相互关联。
想象一下 100 个人将一美元纸币投入一个堆中。然后 100 个不同的人在一天后出现,各自提取一美元。在这个方案中,我们并不知道最初的存款者试图将钱发送给谁。
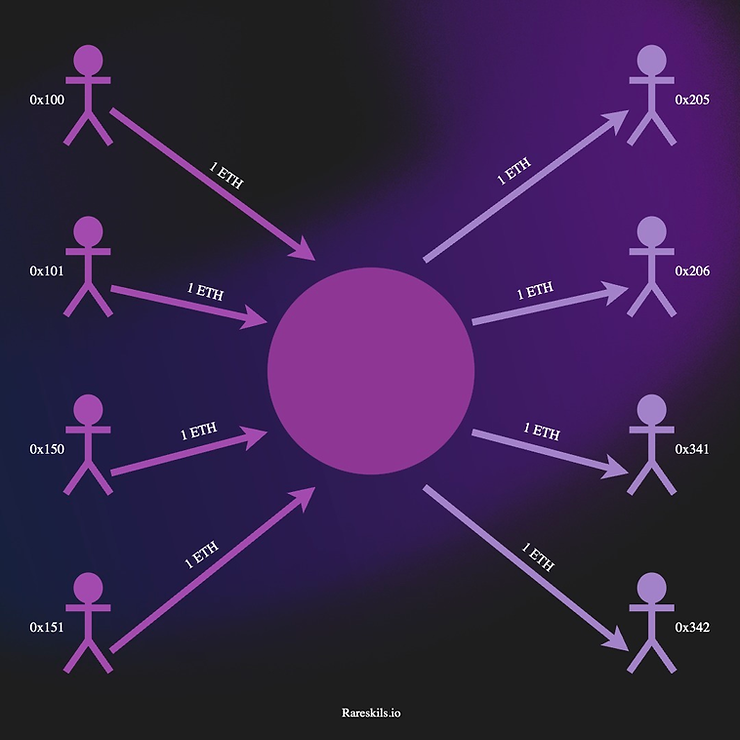
显然,存在一个问题:如果任何人都可以从这堆现金中提取现金,那么它将很快被盗。但如果我们试图留下有关谁被允许撤回的某些元数据,那么这将透露出存款者试图将钱发送给谁。
混合永远无法完全私密
当你将以太坊发送到 Tornado Cash 时,这是完全公开的。当你从 Tornado Cash 提取时,这也完全是公开的。公开的是什么,两者之间的地址无法关联(假设有足够多的其他存款者和撤回者)。
人们能知道的关于一个地址的事情是“这个地址是从 Tornado Cash 获得以太的”或“这个地址向 Tornado Cash 存入了资金”。当一个地址从 Tornado Cash 中撤回时,人们无法确定加密货币是来自哪个存款者。
没有零知识的 Tornado Cash:大量逻辑 OR 的哈希原像证明
让我们尝试在不担心隐私的情况下解决这个问题。
存款者创建两个秘密数字,将它们连接在一起,并在存入以太时将在链上放置其哈希(稍后我们将讨论为什么我们生成两个秘密数字而不是一个)。当几个人存款时,在智能合约中存在几个公共哈希,我们不知道原像是什么。
撤回者出现,撤回者揭示了其中一个哈希的原像(这两个秘密数字)并提取他们的存款。
这显然失败,因为它显示存款者与撤回者之间进行了链下秘密数字的通讯。
然而,如果撤回者可以证明他们知道 一个哈希 的原像,而不揭示 哪个哈希是 和 不揭示该哈希的原像,那么我们就有了一个功能完整的加密货币混合器!
最天真的解决方案是创建一次循环计算,在循环中遍历所有哈希:
zkproof_preimage_is_valid(proof, hash_{1}) OR
zkproof_preimage_is_valid(proof, hash_{2}) OR
zkproof_preimage_is_valid(proof, hash_{3}) OR
...
zkproof_preimage_is_valid(proof, hash_{n-1}) OR
zkproof_preimage_is_valid(proof, hash_{n}) 记住,验证者实际上并没有进行上述计算,因此我们不知道哪个哈希是有效的。验证者(Tornado Cash)只是验证证明者进行了上述计算,并且返回了真值。返回真实的方法无关紧要,只有这样返回的才有意义;它只能在证明者知道某个原像的情况下返回真实。
在这里要重要的是:所有存款哈希都是公开的。当用户存款时,他们提交两个秘密数字的哈希,该哈希是公开的。我们试图掩盖的是撤回者知道哪个哈希的原像。
但这是一个很大的计算。包含大量存款的大循环是非常昂贵的。[1]
我们需要一个数据结构能够紧凑地存储大量哈希,幸运的是我们有:Merkle 树。
使用 Merkle 树存储大量哈希
与其在所有哈希中循环遍历,我们可以说“我知道一个哈希的原像”并且“该哈希在 Merkle 树中”。这达成了与指向一个很长的哈希数组并说“我知道其中一个哈希的原像”相同的目的,只是更加高效。
Merkle 证明在树的大小上是对数级的,因此比我们之前的庞大循环多了些额外的工作。
当加密货币被存入时,用户生成两个秘密数字,连接它们,哈希它们,并将该哈希放入 Merkle 树中。
在撤回时,撤回者提供一个叶子哈希的原像,然后通过 Merkle 证明证明该叶子哈希存在于树中。
这当然将存款者与撤回者关联在一起,但如果我们在零知识的方式中同时进行 Merkle 证明和叶子原像验证,那么链接就破裂了!
零知识证明让我们证明我们针对公众 Merkle 根生成了有效的 Merkle 证明以及叶子的原像,而不需要展示我们如何进行该计算。
仅提供一个零知识证明证明拥有 Merkle 证明和生成根是不够安全的,撤回者还必须证明他们知道叶子的原像。
Merkle 树的叶子都是公开的。每当有人存款时,他们都会提供一个存储在公共中的哈希。由于 Merkle 树是完全公共的,任何人都可以计算任何叶子的 Merkle 证明。
因此,证明一个叶子在树中并不足以防止通过证明伪造带来的盗窃。
撤回者还必须隐私地证明有关该叶子的原像,而不揭示该叶子。请记住,叶子本身是两个数字的哈希。
你可以看到 存款函数 中的 _commitment 参数是公开的。_commitment 变量是添加到树的叶子,它是两个秘密数字的哈希,而存款者并不公开。
/**
@dev 将资金存入该合约。调用者必须发送(对于 ETH)或批准(对于 ERC20)等于或 `denomination` 的值。
@param _commitment 注释承诺,即 PedersenHash(nullifier + secret)
**/
function deposit(bytes32 _commitment) external payable nonReentrant {
require(!commitments[_commitment], "该承诺已被提交");
uint32 insertedIndex = _insert(_commitment);
commitments[_commitment] = true;
_processDeposit();
emit Deposit(_commitment, insertedIndex, block.timestamp);
}实际上,撤回的证明包括证明以下计算已执行:
processMerkleProof(merkleProof, hash(concat(secret1, secret2))) == root这里 processMerkleProof 将 Merkle 证明和叶子作为参数,而 hash(concat(secret1, secret2)) 产生的则是叶子。
在 Tornado Cash 的上下文中,验证者是 Tornado Cash 智能合约,它将向提供有效证明的人转移资金。
证明者是撤回者,他们可以证明他们进行哈希计算以产生其中一个叶子。一般而言,唯一可以撤回的人是存款者,因为他们将是唯一能证明他们知道哈希原像的参与者。当然,这个用户必须使用一个不同且完全不相关的地址进行撤回!
撤回者实际上执行上述计算(Merkle 证明和叶子哈希生成),生成 zk-proof 以证明他们正确地进行了操作,然后将此证明提供给智能合约。
merkleProof 和 {secret1, secret2} 在证明中是隐藏的,但凭借计算证明,验证者可以验证撤回者实际上运行了该计算以正确生成叶子和 Merkle 根。
所以让我们总结一下:
- 存款者:
- 生成两个秘密数字并从它们的连接中创建承诺哈希
- 提交一个承诺哈希
- 向 Tornado Cash 转移加密货币
- Tornado Cash:
- 在存款阶段:
- 将承诺哈希添加到 Merkle 树中
- 在存款阶段:
- 撤回者:
- 为 Merkle 根生成有效的 Merkle 证明
- 从两个秘密数字生成承诺哈希
- 生成上述计算的 zk-proof
- 向 Tornado Cash 提交证明
- Tornado Cash
- 在撤回阶段:
- 验证证明是否与 Merkle 根匹配
- 将加密货币转移到撤回者
- 在撤回阶段:
防止多次撤回
上述方案存在一个问题:什么阻止我们进行多次撤回?显然,我们需要“移除” Merkle 树中的叶子,以便记录已撤回的存款,但这将揭示哪个存款是我们的!
Tornado cash 通过不从 Merkle 树中移除叶子来处理此问题。一旦叶子添加到 Merkle 树中,它将永远留在那里。
为了防止多次撤回,智能合约使用一种称为“nullifier 方案”的机制,这在零知识应用和协议中非常常见。
Nullifier 方案
在零知识中,nullifier 方案类似于一种独特的 nonce,提供了一层匿名性。
很明显,为什么叶子由两个秘密数字构成,而不是一个。
输入存款哈希的两位数字是 nullifier 和一个秘密,叶子的哈希是 concat(nullifier, secret) 的哈希,顺序是这样的。
在撤回过程中,用户必须提交 nullifier 的哈希,也就是 nullifierHash,并证明他们连接了 nullifier 和 secret,并对其进行了哈希以生成其中一个叶子。智能合约可以使用零知识算法验证发送者真的知道 nullifier 哈希的原像。
nullifier 哈希被添加到一个映射中,以确保它不会被重用。
这就是我们需要两个秘密数字的原因。如果我们揭示了这两个数字,那么我们就会知道撤回者所针对的哪个叶子!通过仅揭示一个组成数字,无法确定其关联的叶子。
记住,零知识证明验证无法给出私密输入的 nullifier,仅能验证计算、输出和证明是否一致。这就是用户必须提交公共 nullifierHash 和证明,他们从隐藏的 nullifier 中计算出的原因。
你可以在 Tornado Cash 的 withdraw 函数 中看到这个逻辑。

让我们总结一下。用户必须证明:
- 他们知道叶子的原像
- nullifier 未被之前使用过(这只是一个简单的 solidity 映射,而不是一个 zk 验证步骤)
- 他们可以生成 nullifier 哈希和 nullifier 的原像
以下是可能的结果:
- 用户提供错误的 nullifier:检查 nullifier 和 nullifier 原像的 zk 证明将不通过
- 用户提供错误的 secret:叶子原像的 zk 证明将不通过
- 用户提供错误的 nullifier 哈希(以绕过第 86 行的检查):nullifier 和 nullifier 原像的 zk 证明将不通过
增量 Merkle 树是一个省 gas 的 Merkle 树
你可能注意到,在上述解释中,我们快得过于简单了。如何在链上更新 Merkle 树而不耗尽 gas?存款量很可能是很多,计算整个过程的成本是难以承受的。
增量 Merkle 树通过一些巧妙的优化来解决这些限制。但在探讨优化之前,我们需要理解限制。
增量 Merkle 树是一棵固定深度的 Merkle 树,每个叶子开始时都是零值,通过逐一替换从左到右的零叶来添加非零值。
下面的动画演示了一棵深度为 3 的增量 Merkle 树,最多可以容纳 8 个叶子。遵循我们对 Tornado Cash 的域术语,我们称这些为“承诺”,标记变量 Ci。
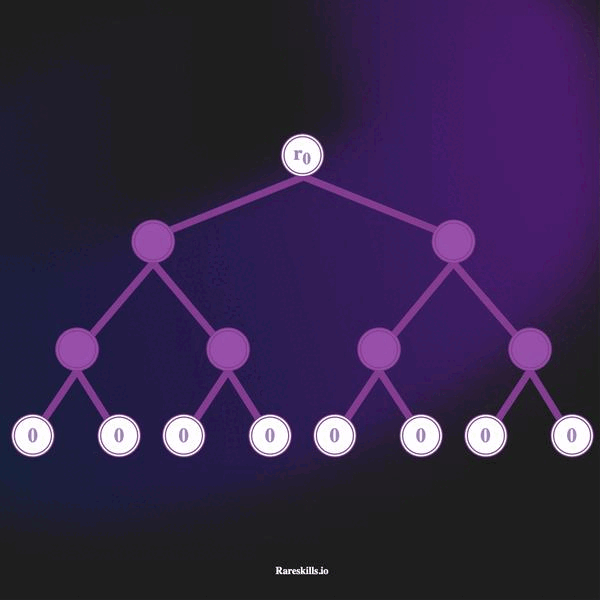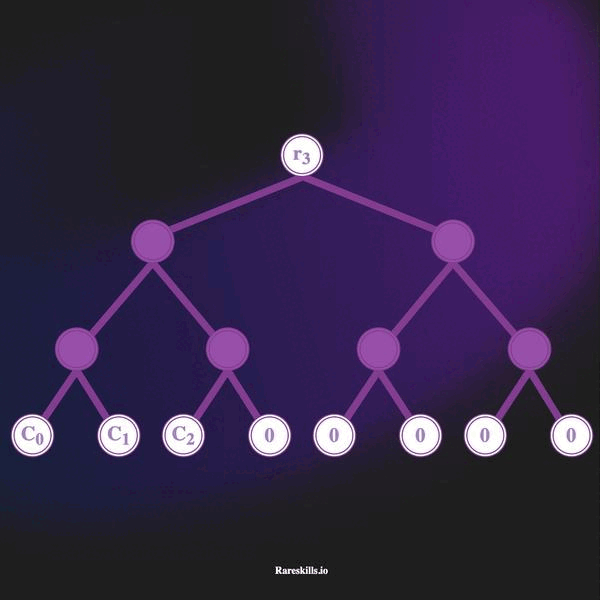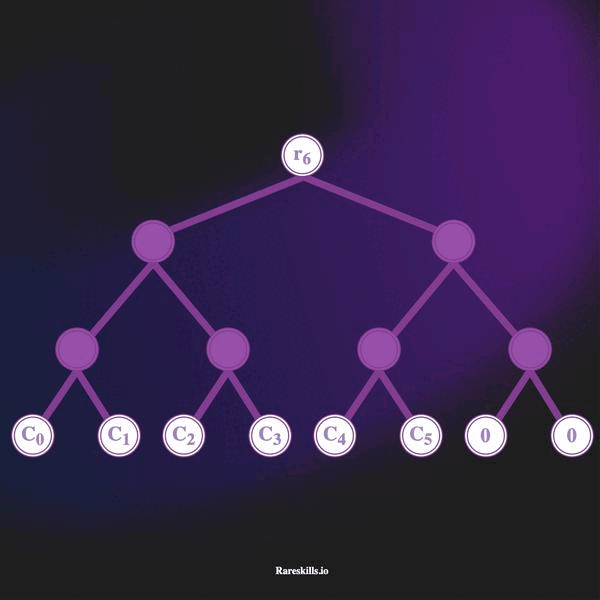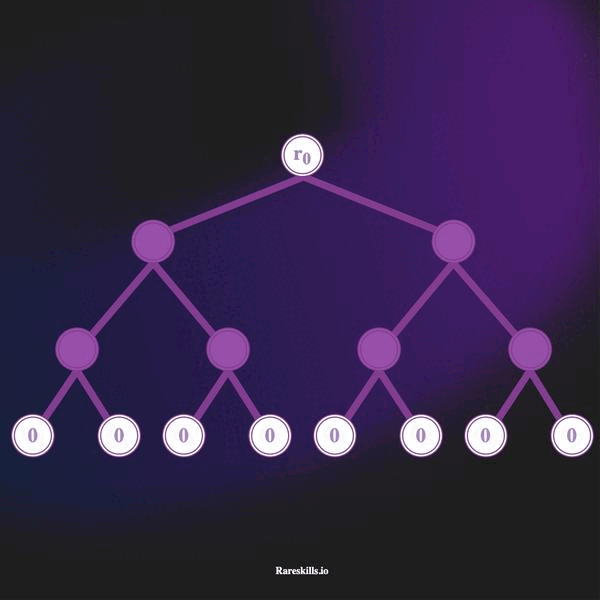
以下是增量 Merkle 树的一些重要特性:
- Merkle 树的深度固定为 32。这意味着它无法处理超过
2^32 - 1的存款。(这是 Tornado Cash 所选的一个任意深度,但需要保持恒定)。 - Merkle 树开始时是一棵所有叶子均为
hash(bytes32(0))的树。 - 随着存款的进行,最左侧未使用的叶子将被承诺哈希覆盖。存款以“从左到右”的方式添加到叶子中。
- 一旦存款被添加到 Merkle 树中,则无法移除。
- 每进行一次新存款便会存储一个新的根。Tornado Cash 将其称为“带历史的 Merkle 树”。因此,Tornado Cash 存储的是一系列 Merkle 根,而不是单一的根。显然,Merkle 根在成员添加时会发生变化。
现在我们面临一个问题:在...

- 学分: 0
- 分类: 以太坊
- 标签: Tornado Cash 零知识证明 Merkle Tree 智能合约 匿名转账 Solidity



